Data¶

What is Machine Learning¶
Machine learning is automated process that extracts patterns from data. To illustrate basic concepts of machine learning we will use supervised machine learning that automatically learns and builds model of relationships between a set of descriptive features and a target feature (labels) based on a set of historical examples or instances. We can then use this model to make predictions for new instances unseen in learning period.
Following schema illustrates common process of machine learning.
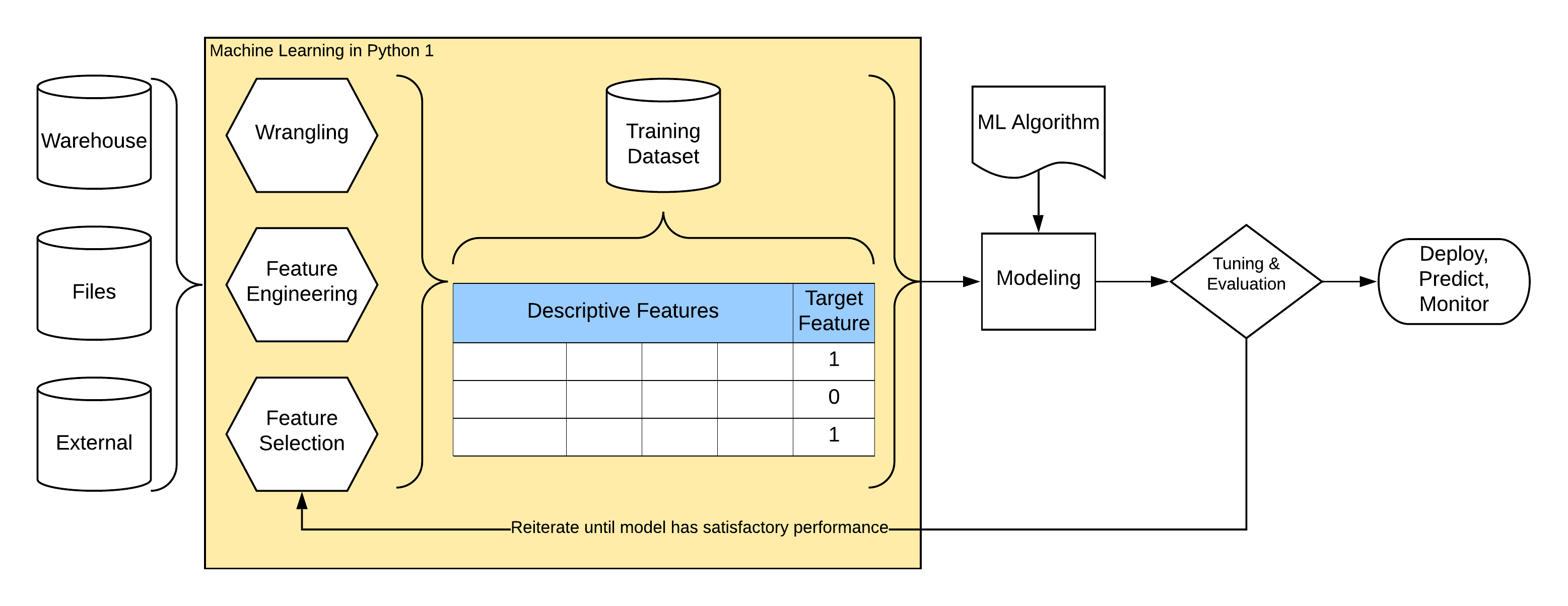
Steps in “Almost Every” Data Problem¶
Define the Problem¶
We are gonna predict whether it rains tomorrow from today’s data in locations all over Australia.
It is a binary classification problem, we want also some insights into what features and their values signal rain tomorrow (if any). We got data from Australian Weather Bureau for education purposes and downloaded the dataset from Kaggle Weather dataset.

Python¶
We will use following libraries in this lecture



# import some basic libraries to do analysis and ML
import pandas as pd
import numpy as np
import sklearn as sk
import scipy.stats as st
import warnings
warnings.filterwarnings('ignore')
# Visualization details
import plotly.io as pio
import plotly.express as px
import plotly.offline as py
import plotly.graph_objects as go
import machine_learning_python as mlp
png_renderer = pio.renderers['png']
png_renderer.height = 400
png_renderer.width = 800
pio.renderers.default = 'png'
Load and Get to Know Your Data¶
We load data and have the first look on what is available to us, what features we have, their types, missing values, what might be wrong, what we can fix on our side, what has to be fixed with data provider etc.
It is worth to validate the basic assumptions about the data:
Do we have anough samples?
Are basic axioms valid eg. uniqueness of ids, having one measurement per day, …
What labels do we have? Is it binary?
Some features that are available to us:
RainTomorrow is our binary target (dependent) features we will be predicting or explaining using descriptive (independent) features.
Date, Location are nominal (categorical) features spanning Australia and about 9 years of measurements. We will need to convert it to numerical features. Some locations are close together, some are very distant, we could probably use location to give information about adjacent rain and combine it with wind direction.
WindDirs are nominal features about wind direction. We will have to convert it to numerical features.
RainToday is nominal info about raining today. We will have to convert it to numerical features. It will be probably the feature with the most signal as it is likely that when it rains today, it will rain tomorrow.
RISK_MM feature stands out, it looks like some technical measure, we will have to check later.
There is a group of numerical features describing morning and afternoon measurements. We have to check distributions and fill in missing values.
# Read data from local .csv file
df = pd.read_csv('../../data/weatherAUS.csv')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 142193 entries, 0 to 142192
Data columns (total 24 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 142193 non-null object
1 Location 142193 non-null object
2 MinTemp 141556 non-null float64
3 MaxTemp 141871 non-null float64
4 Rainfall 140787 non-null float64
5 Evaporation 81350 non-null float64
6 Sunshine 74377 non-null float64
7 WindGustDir 132863 non-null object
8 WindGustSpeed 132923 non-null float64
9 WindDir9am 132180 non-null object
10 WindDir3pm 138415 non-null object
11 WindSpeed9am 140845 non-null float64
12 WindSpeed3pm 139563 non-null float64
13 Humidity9am 140419 non-null float64
14 Humidity3pm 138583 non-null float64
15 Pressure9am 128179 non-null float64
16 Pressure3pm 128212 non-null float64
17 Cloud9am 88536 non-null float64
18 Cloud3pm 85099 non-null float64
19 Temp9am 141289 non-null float64
20 Temp3pm 139467 non-null float64
21 RainToday 140787 non-null object
22 RISK_MM 142193 non-null float64
23 RainTomorrow 142193 non-null object
dtypes: float64(17), object(7)
memory usage: 26.0+ MB
df.sample(5)[df.columns[:10]]
| Date | Location | MinTemp | MaxTemp | Rainfall | Evaporation | Sunshine | WindGustDir | WindGustSpeed | WindDir9am | |
|---|---|---|---|---|---|---|---|---|---|---|
| 30483 | 2010-10-16 | Sydney | 11.7 | 16.1 | 0.8 | 3.4 | 9.3 | WNW | 85.0 | W |
| 97563 | 2010-08-10 | MountGambier | 2.2 | 14.8 | 0.0 | 1.2 | 0.7 | S | 61.0 | SE |
| 70928 | 2016-10-10 | Mildura | 11.4 | 17.5 | 0.2 | NaN | 8.4 | W | 46.0 | W |
| 107169 | 2012-04-15 | Albany | 12.9 | 24.7 | 0.0 | 3.0 | 10.1 | NaN | NaN | NW |
| 107729 | 2013-12-28 | Albany | 13.8 | 21.5 | 0.0 | 5.2 | 13.3 | NaN | NaN | E |
df.sample(5)[df.columns[10:20]]
| WindDir3pm | WindSpeed9am | WindSpeed3pm | Humidity9am | Humidity3pm | Pressure9am | Pressure3pm | Cloud9am | Cloud3pm | Temp9am | |
|---|---|---|---|---|---|---|---|---|---|---|
| 77540 | WSW | 13.0 | 19.0 | 71.0 | 53.0 | 1024.1 | 1023.9 | 7.0 | 7.0 | 14.9 |
| 84382 | SE | 9.0 | 15.0 | 65.0 | 62.0 | 1020.8 | 1018.3 | 7.0 | 7.0 | 25.9 |
| 51550 | ESE | 6.0 | 13.0 | 97.0 | 93.0 | NaN | NaN | NaN | NaN | 1.1 |
| 120428 | SW | 13.0 | 20.0 | 55.0 | 49.0 | 1015.9 | 1013.1 | 1.0 | 1.0 | 23.2 |
| 6241 | W | 13.0 | 4.0 | 46.0 | 24.0 | 1021.7 | 1018.6 | 2.0 | 3.0 | 25.3 |
df.sample(5)[df.columns[20:]]
| Temp3pm | RainToday | RISK_MM | RainTomorrow | |
|---|---|---|---|---|
| 103697 | 33.4 | No | 0.0 | No |
| 123453 | 18.2 | No | 0.0 | No |
| 103916 | 30.8 | No | 0.0 | No |
| 55750 | 18.6 | No | 18.4 | Yes |
| 18195 | 15.3 | No | 1.8 | Yes |
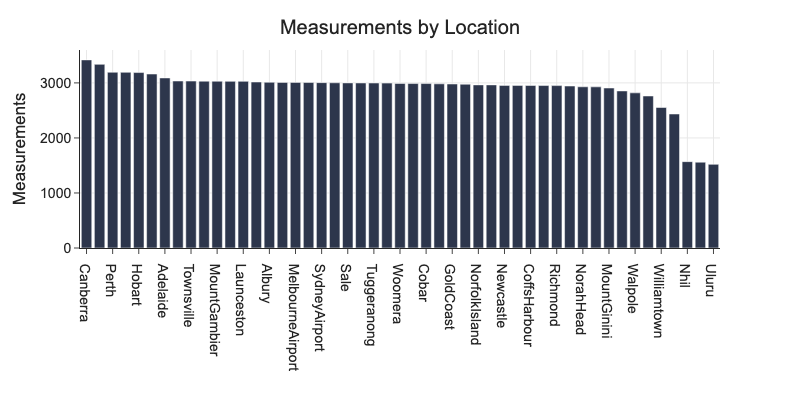
d = df.groupby('Location').agg(Count=('Date', 'count')).sort_values('Count', ascending=False)
print(f'We have {df.Location.nunique()} unique locations.')
print(f'We have {df.Date.nunique()} days or {df.Date.nunique() // 365}+ years of measurements.')
We have 49 unique locations.
We have 3436 days or 9+ years of measurements.
Check for duplicated data.
df.groupby(['Location', 'Date']).size().sort_values(ascending=False).head(5)
Location Date
Adelaide 2008-07-01 1
PerthAirport 2013-11-07 1
2013-11-01 1
2013-11-02 1
2013-11-03 1
dtype: int64
For some locations, we have only about half of samples of other locations.
px.bar(d, x=d.index, y='Count', title='Measurements by Location', labels={'Count': 'Measurements', 'Location': ''})
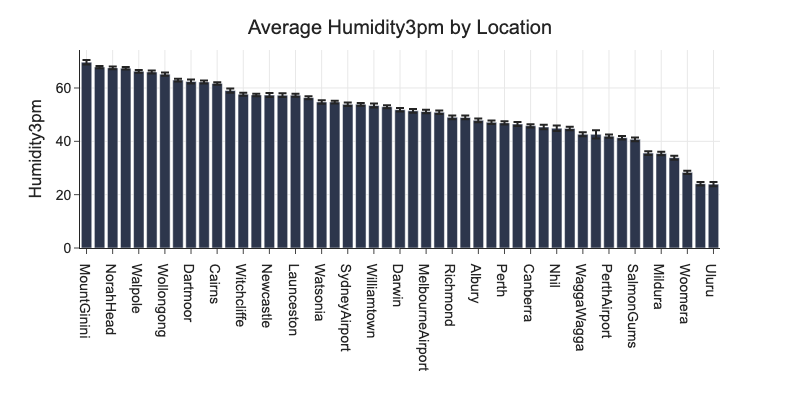
# average humidity by location
d = df.groupby('Location')[['Humidity3pm']].agg(
cnt=('Humidity3pm', 'count'),
m=('Humidity3pm', 'mean'),
se=('Humidity3pm', 'sem')).reset_index()
d['ci'] = d.se * st.t.ppf(0.975, d.cnt - 1)
fig = px.bar(d, x='Location', y='m', error_y='ci', title='Average Humidity3pm by Location', labels={'m': 'Humidity3pm', 'Location': ''})
fig.update_layout(barmode='stack', xaxis={'categoryorder':'total descending'})
Complete, Correct, Create, and Convert¶
df.isnull().sum().sort_values(ascending=False)
Sunshine 67816
Evaporation 60843
Cloud3pm 57094
Cloud9am 53657
Pressure9am 14014
Pressure3pm 13981
WindDir9am 10013
WindGustDir 9330
WindGustSpeed 9270
WindDir3pm 3778
Humidity3pm 3610
Temp3pm 2726
WindSpeed3pm 2630
Humidity9am 1774
RainToday 1406
Rainfall 1406
WindSpeed9am 1348
Temp9am 904
MinTemp 637
MaxTemp 322
RISK_MM 0
Date 0
Location 0
RainTomorrow 0
dtype: int64
There are locations completely missing values for Pressure9am, WindGustSpeed, Pressure3pm. Measurement device is probably not present at these locations at all.
Dropping does not make sense here, we would lose whole locations.
Bear in mind that we will have to implement this selective imputation everywhere we prepare data for this model. We will check later if this imputation is worth it.
g = df.groupby('Location').agg(Pressure9amCount=('Pressure9am', 'count'),
Pressure3pmCount=('Pressure3pm', 'count'),
WindGustSpeedCount=('WindGustSpeed', 'count'))
g[g.Pressure9amCount == 0]
| Pressure9amCount | Pressure3pmCount | WindGustSpeedCount | |
|---|---|---|---|
| Location | |||
| MountGinini | 0 | 0 | 2715 |
| Newcastle | 0 | 0 | 0 |
| Penrith | 0 | 0 | 2957 |
| SalmonGums | 0 | 0 | 2909 |
print(f'If we drop rows with at least one value missing, we get {df.dropna().shape[0]:,} \
out of {df.shape[0]:,} instances.')
If we drop rows with at least one value missing, we get 56,420 out of 142,193 instances.
Complete¶
Common strategy is to drop rows with missing values. This could mean dropping substantial amount of data and not being able to predict for many data samples in production. It is always best to check why data are missing and fix them in data collection phase.
Strategies to populate missing values are:
Use models that are tolerant to missing values like naive bayes or decision trees.
Populate categorical data with mode.
Populate numerical data with mean/median, or using group average.
Predict missing values using regression from other columns.
We have features with many missing values eg. Sunshine and features with some missing values eg. Temp3pm probably caused by some malfunction of a measuring unit.
Columns Evaporation, Sunshine, Cloud9am, Cloud3pm have many missing values. We fill-in values using iterative regression on few selected features. When many values are missing in some feature, it is worth to add indicator feature informing ML algorithm that particular value was imputed.
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
df['RainToday'] = df['RainToday'].replace({'Yes': 1, 'No': 0})
df['RainTomorrow'] = df['RainTomorrow'].replace({'Yes': 1, 'No': 0})
cols = ['Evaporation', 'Sunshine', 'Cloud9am', 'Cloud3pm', 'Humidity9am', 'Humidity3pm', 'RainToday']
imp = IterativeImputer(initial_strategy='median', add_indicator=True).fit_transform(df[cols].values)
d = pd.DataFrame(imp, columns=cols + [f'{c}_missing' for c in cols])
d.head()[['Evaporation', 'Evaporation_missing', 'Sunshine', 'Sunshine_missing']]
| Evaporation | Evaporation_missing | Sunshine | Sunshine_missing | |
|---|---|---|---|---|
| 0 | 6.251375 | 1.0 | 6.960355 | 1.0 |
| 1 | 8.201791 | 1.0 | 10.762692 | 1.0 |
| 2 | 8.671174 | 1.0 | 11.255441 | 1.0 |
| 3 | 8.275212 | 1.0 | 11.644286 | 1.0 |
| 4 | 4.537052 | 1.0 | 4.875672 | 1.0 |
d[['Evaporation', 'Evaporation_missing', 'Sunshine', 'Sunshine_missing']].describe()
| Evaporation | Evaporation_missing | Sunshine | Sunshine_missing | |
|---|---|---|---|---|
| count | 142193.000000 | 142193.000000 | 142193.000000 | 142193.000000 |
| mean | 5.244790 | 0.427890 | 7.430390 | 0.476929 |
| std | 3.475205 | 0.494775 | 3.374164 | 0.499469 |
| min | -0.401327 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 2.979168 | 0.000000 | 5.014699 | 0.000000 |
| 50% | 4.800000 | 0.000000 | 7.717306 | 0.000000 |
| 75% | 6.800000 | 1.000000 | 10.100000 | 1.000000 |
| max | 145.000000 | 1.000000 | 37.475535 | 1.000000 |
# replace imputed columns including indicators
# cols_wo_rt = [c for c in cols if 'RainToday' not in c]
# df.drop(cols_wo_rt, axis=1, inplace=True)
# cols_wo_rt = cols_wo_rt + [f'{c}_missing' for c in cols if 'RainToday' not in c]
# df = pd.concat([df, d[cols_wo_rt]], axis=1)
df['RainToday'] = df['RainToday'].fillna(0)
Impute the rest with median for numerical features and mode for categorical features.
from sklearn.impute import SimpleImputer
impute_columns_numerical = ['WindGustSpeed', 'Pressure9am', 'Pressure3pm', 'Temp3pm', 'WindSpeed3pm',
'Rainfall', 'WindSpeed9am', 'Temp9am', 'MinTemp', 'MaxTemp', 'Evaporation',
'Sunshine', 'Cloud9am', 'Cloud3pm', 'Humidity9am', 'Humidity3pm']
impute_columns_categorical = ['WindGustDir', 'WindDir9am', 'WindDir3pm']
for c in impute_columns_numerical:
df[c] = SimpleImputer(strategy='median').fit_transform(df[c].values.reshape(-1, 1))
for c in impute_columns_categorical:
df[c] = SimpleImputer(strategy='most_frequent').fit_transform(df[c].values.reshape(-1, 1))
Check that we handled everything.
df.isnull().sum().sort_values(ascending=False).head()
Date 0
Location 0
RISK_MM 0
RainToday 0
Temp3pm 0
dtype: int64
Correct¶
We review data for striking errors caused by eg. transformations of data on the source, manual input errors, having numerical feature values as nominal (because 1 is not the same as "1"), etc.
# basic overview about distribution of values in numerical columns
cols = ['Cloud9am', 'Humidity9am']
df[cols].describe()
| Cloud9am | Humidity9am | |
|---|---|---|
| count | 142193.000000 | 142193.000000 |
| mean | 4.649568 | 68.858235 |
| std | 2.294357 | 18.932512 |
| min | 0.000000 | 0.000000 |
| 25% | 3.000000 | 57.000000 |
| 50% | 5.000000 | 70.000000 |
| 75% | 6.000000 | 83.000000 |
| max | 9.000000 | 100.000000 |
# boxplots
m = pd.melt(df[cols + ['Date', 'Location']], id_vars=['Date', 'Location'], value_vars=cols)
fig = px.box(m, y='value', facet_col='variable', points='outliers', height=400)
fig.update_yaxes(dict(matches=None, showticklabels=True), row=1, col=2)
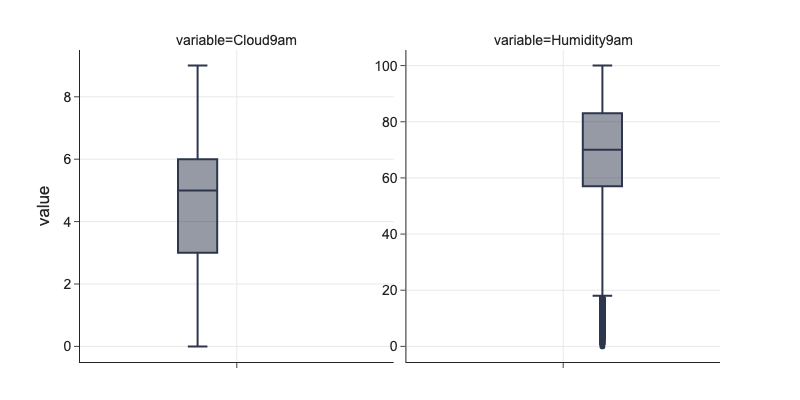
Outliers¶
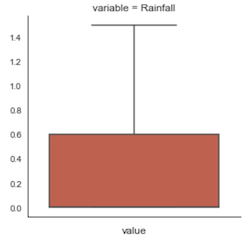
Outliers in data could be real eg. some flooding in Rainfall or could come from faulty measurement. Outliers skew mean of the feature and some ML algorithms calculating distances like linear models for both classification and regression are sensitive to them.
There are different techniques how to handle outliers:
Cap values to stay inside inter quartile range.
Bin numerical feature to create categorical values.
Apply function transformation that penalizes long-tail outliers eg. taking \(log\) of values.
We cap numerical feature values \(v\) to stay be within
Where
\(q_1\) is 25% quartile
\(q_3\) is 75% quartile
\(\text{IQR} = q_3 - q_1\) is inter-quartile range
\(m\) is constant
IQR is defined as difference between value on 75% quartile (\(q_3\)) and 25% quartile (\(q_1\)). We can use different multiples of IQR for different features, common practice is using \(m = 1.5\) or \(m = 1.8\).
q1 = df[cols].quantile(0.25)
q3 = df[cols].quantile(0.75)
iqr = q3 - q1
df[cols] = df[cols].clip(q1 - 1.5*iqr, q3 + 1.5*iqr, axis=1)
df[cols].describe()
| Cloud9am | Humidity9am | |
|---|---|---|
| count | 142193.000000 | 142193.000000 |
| mean | 4.649568 | 68.911015 |
| std | 2.294357 | 18.779092 |
| min | 0.000000 | 18.000000 |
| 25% | 3.000000 | 57.000000 |
| 50% | 5.000000 | 70.000000 |
| 75% | 6.000000 | 83.000000 |
| max | 9.000000 | 100.000000 |
# fixed distributions
cols = ['MinTemp', 'Rainfall', 'WindGustSpeed']
m = pd.melt(df[cols + ['Date', 'Location']], id_vars=['Date', 'Location'])
fig = px.box(m, y='value', facet_col='variable', height=400)
fig.update_yaxes(dict(matches=None, showticklabels=True), row=1, col=2)
fig.update_yaxes(dict(matches=None, showticklabels=True), row=1, col=3)
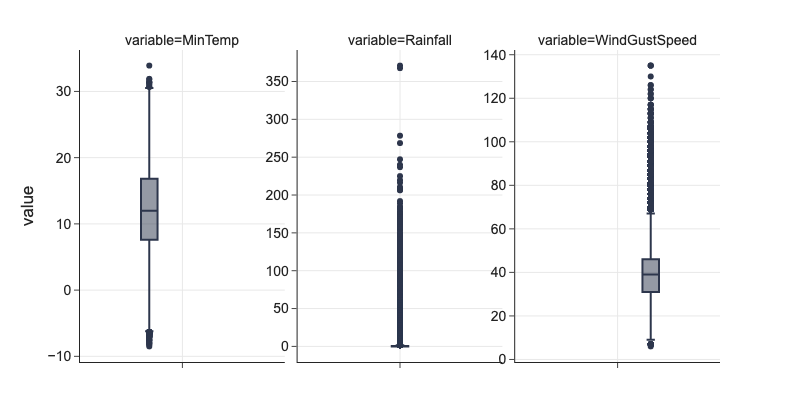
Irregular Cardinality¶
Some numerical features might be better represented as categorical features because they are coded as ordinal numbers (eg. sex coded as 0 and 1) or because they can have only some specified values.
All our numerical columns seem to have reasonable cardinality and there is probably no candidate for categorical type among numerical features.
df.nunique().sort_values().head(15)
RainTomorrow 2
RainToday 2
Cloud3pm 10
Cloud9am 10
WindDir3pm 16
WindDir9am 16
WindGustDir 16
WindSpeed9am 43
WindSpeed3pm 44
Location 49
WindGustSpeed 67
Humidity9am 83
Humidity3pm 101
Sunshine 145
Evaporation 356
dtype: int64
Create¶
We can use our domain knowledge and available features to create new features to determine if they have signal for predicted outcome. We can parse string features, combine features to discover good interactions and amplification effect. We can also crawl data to enhance data points with historical trends, local context, and additional data sources that are available to us (eg. satelite images) and are joinable to existing data.
We check if there was a drop or rise between morning and afternoon pressure.
df['PressureDiff'] = df['Pressure3pm'] - df['Pressure9am']
df['PressureDrop'] = df['PressureDiff'].map(lambda l: 1 if l < 0 else 0)
We include it as an indicator and also as absolute value to check what works better in following exploratory data analysis.
Date/Time Features¶
Date and time data usually provide valuable contextual information but we have to transform the data to make it accessible for ML algorithms. Some ML algorithms can work on time series data and learn trends like periodicity.
Common strategies:
Extract year, months, days, week days into separate columns to give the model some information about possible periodicity. This is useful eg. when we process transactional data as weekends are always different from weekdays.
Extract time period between events in data. Eg. how long it was from the last event to the data point.
Use dates to connect data from additional datasets like holidays, weekends, eg. Facebook Prophet.
Downside being that when using model in production to predict on one measurement, we have to load preceeing measurements to calculate values for these features. In real-time setting, this requires database lookups.
We extract Year and Month features here. We also add DaysSinceRainWeek to capture how many days passed from the last rain day in rolling week and RainDaysWeek to capture how many days with rain there was in rolling week.
# Extract year and month
df['DateD'] = pd.to_datetime(df.Date, format='%Y-%m-%d')
df['Year'] = df['DateD'].dt.year.astype('category')
df['Month'] = df['DateD'].dt.month.astype('category')
df['YearMonth'] = df[['Year', 'Month']].apply(lambda r: f'{r[0]}-{r[1]:02d}', axis=1)
df[['Date', 'Year', 'Month', 'YearMonth']].head(5)
| Date | Year | Month | YearMonth | |
|---|---|---|---|---|
| 0 | 2008-12-01 | 2008 | 12 | 2008-12 |
| 1 | 2008-12-02 | 2008 | 12 | 2008-12 |
| 2 | 2008-12-03 | 2008 | 12 | 2008-12 |
| 3 | 2008-12-04 | 2008 | 12 | 2008-12 |
| 4 | 2008-12-05 | 2008 | 12 | 2008-12 |
def agg_days_since_rain(x):
x = x[:-1]
r = np.argmax(np.flip(x)) + 1 if x.any() else 20
return r
def agg_rain_days(x):
return np.sum(x[:-1])
def rolling_feature(d, by, on, val, window, name, agg_fce):
cs = [by, on]
r = d.sort_values(cs).groupby(by).rolling(window, on=on, min_periods=1)
agg = r.apply(agg_fce, raw=True)
agg[name] = agg[val] # agg has aggregated values in column val
agg.drop([val, on], axis=1, inplace=True)
agg.rename_axis(index=(by, 'Id'), inplace=True)
agg.reset_index(inplace=True)
return agg
Contextual Features¶
We can look beyond single row of data to calculate some contextual features. Keep in mind that when in production mode, we would need to load context for every row we want to predict for from somewhere. In current setting, we can cheaply evaluate if adding such features help performance of the model.
We use last 7 days of data per Location to calculate features
RainDaysWeek capturing how many times it rained in the last week (excluding given day)
DaysSinceRainWeek capturing how long it is since the last rainy day in the last week.
# Rolling_feature is custom rolling window function that takes different aggregation functions
dsrw = rolling_feature(df[['DateD', 'Location', 'RainToday']], 'Location', 'DateD', 'RainToday', 8, 'DaysSinceRainWeek', agg_days_since_rain)
rdw = rolling_feature(df[['DateD', 'Location', 'RainToday']], 'Location', 'DateD', 'RainToday', 8, 'RainDaysWeek', agg_rain_days)
# Prepare original dataset to have the same index as rv
d = df.copy()
d.set_index(['Location'], append=True, inplace=True)
d.rename_axis(('Id', 'Location'), inplace=True)
d.reset_index(inplace=True)
# Merge new features and drop technical columns
d = d.merge(dsrw, on=['Id', 'Location'])
d = d.merge(rdw, on=['Id', 'Location'])
d['NoRainWeek'] = d['DaysSinceRainWeek'].map(lambda l: 1 if l == 20 else 0)
d['DaysSinceRainWeek'] = d['DaysSinceRainWeek'].replace({20: 0})
d[(d.Location == 'Melbourne')][['Date', 'Location', 'RainToday', 'DaysSinceRainWeek', 'NoRainWeek', 'RainDaysWeek']].head(10)
| Date | Location | RainToday | DaysSinceRainWeek | NoRainWeek | RainDaysWeek | |
|---|---|---|---|---|---|---|
| 65745 | 2008-07-01 | Melbourne | 1.0 | 0.0 | 1 | 0.0 |
| 65746 | 2008-07-02 | Melbourne | 0.0 | 1.0 | 0 | 1.0 |
| 65747 | 2008-07-03 | Melbourne | 1.0 | 2.0 | 0 | 1.0 |
| 65748 | 2008-07-04 | Melbourne | 0.0 | 1.0 | 0 | 2.0 |
| 65749 | 2008-07-05 | Melbourne | 0.0 | 2.0 | 0 | 2.0 |
| 65750 | 2008-07-06 | Melbourne | 0.0 | 3.0 | 0 | 2.0 |
| 65751 | 2008-07-07 | Melbourne | 0.0 | 4.0 | 0 | 2.0 |
| 65752 | 2008-07-08 | Melbourne | 1.0 | 5.0 | 0 | 2.0 |
| 65753 | 2008-07-09 | Melbourne | 1.0 | 1.0 | 0 | 2.0 |
| 65754 | 2008-07-10 | Melbourne | 1.0 | 1.0 | 0 | 3.0 |
df = d
Convert¶
Some ML algorithms cannot handle non-numeric values in features like linear models or neural nets. We have to encode categorical features using either dummy values or better using one-hot encoding which helps with colinear features. It is good practice to encode categorical values also for ML algorithms that can handle them like decision trees and forrests of trees to be able to test, use, and combine multiple algorithms.
Categorical Features to Numerical¶
df[['WindGustDir', 'Location', 'Year']].head(5)
| WindGustDir | Location | Year | |
|---|---|---|---|
| 0 | W | Albury | 2008 |
| 1 | WNW | Albury | 2008 |
| 2 | WSW | Albury | 2008 |
| 3 | NE | Albury | 2008 |
| 4 | W | Albury | 2008 |
We need to convert categorical values into numerical because many ML algorithms can handle only float numbers on input. We cannot simply assign natural numbers to categories, because numbers encode ordering implicitly and this is then picked by models. For example if we encode North as 0 and South as 1, South is greater than North.
One-hot Encoding¶
One-hot encoding encodes categorical or ordinal features as nominal using “flag columns” or “dummy values” of zeros and ones.
When you have \(N\) distinct values in some feature, we need \(N-1\) flag columns to represent it. The \(N\)th value is represented with all flag columns of zeros. This helps with ML algorithms that are sensitive to colinearity eg. linear and logistic regression without regularization and neural nets.
from sklearn.preprocessing import OneHotEncoder
v = df['WindGustDir'].values.reshape(-1, 1)
e = OneHotEncoder(drop='first', sparse=False).fit(v)
p = pd.DataFrame(e.transform(v), columns=e.categories_[0][1:])
d = pd.concat([df['WindGustDir'], p], axis=1)
d.head(5)
| WindGustDir | ENE | ESE | N | NE | NNE | NNW | NW | S | SE | SSE | SSW | SW | W | WNW | WSW | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | W | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | WNW | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | WSW | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | NE | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | W | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
East WindGustDir is encoded using all zeros in remaining flag columns.
d[d.WindGustDir == 'E'].head(3)
| WindGustDir | ENE | ESE | N | NE | NNE | NNW | NW | S | SE | SSE | SSW | SW | W | WNW | WSW | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 76 | E | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 167 | E | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 169 | E | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
Exploratory Data Analysis¶
We explore values in available features to learn their distributions, evaluate their impact on target feature, learn how they interact and study them in detail. The output are learnings, detailed questions to data providers, knowing what transformations we have to apply to data before passing them to ML algorithm.
Categorical Feature¶
We could check proportion of positive level of target feature in different levels of categorical feature.
Plotting of confidence intervals gives us some idea about the absolute number and variance of samples in every level of categorical feature.
categorical_columns = list(df.select_dtypes(['object']).columns) + ['PressureDrop', 'RainToday']
categorical_columns
['Location',
'Date',
'WindGustDir',
'WindDir9am',
'WindDir3pm',
'YearMonth',
'PressureDrop',
'RainToday']
png_renderer.height = 800
png_renderer.width = 1000
d = mlp.eda_categorical(df, 'RainTomorrow', max_categorical_values=12)
fig = px.bar(d, x='value', y='mean', error_y='ci', facet_col='variable',
facet_col_wrap=3,
labels={'value': '', 'mean': 'RainTomorrow'})
fig.update_xaxes(dict(matches=None, showticklabels=True))
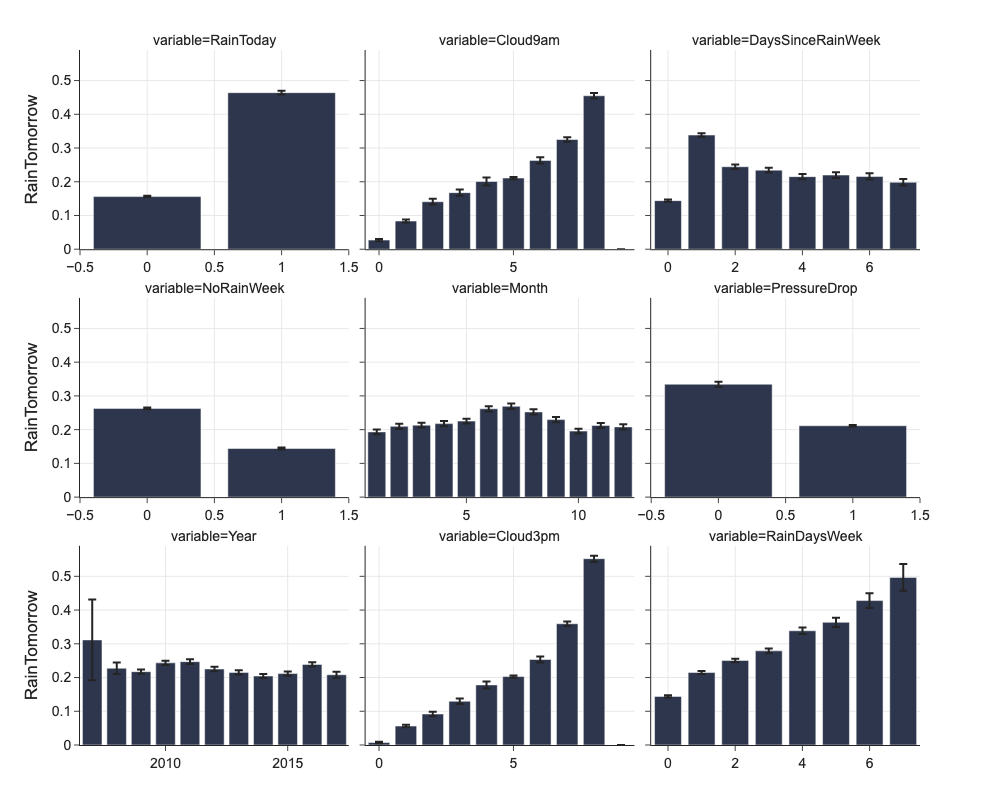
# Annual and monthly rainy days
png_renderer.height = 400
fig = px.bar(d[d.variable.isin(['Year', 'Month'])], x='value', y='mean', error_y='ci', facet_col='variable',
facet_col_wrap=2,
labels={'value': '', 'mean': 'RainTomorrow'})
fig.update_xaxes(dict(matches=None, showticklabels=True))
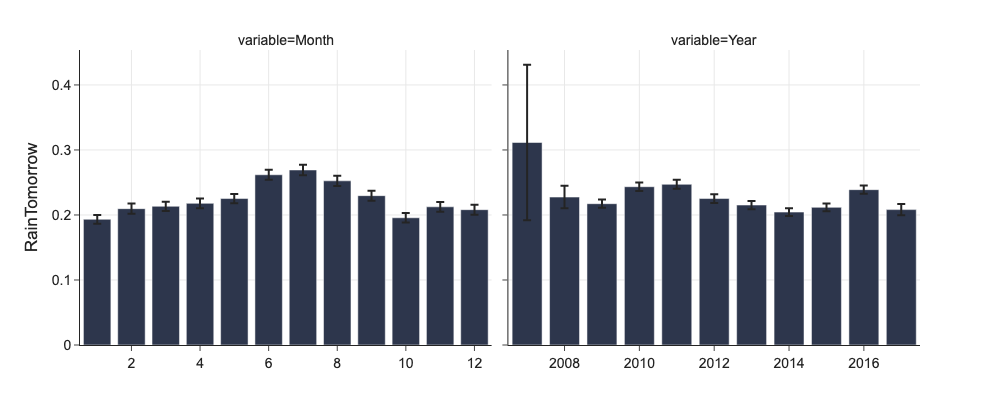
# Annual and monthly rainy days
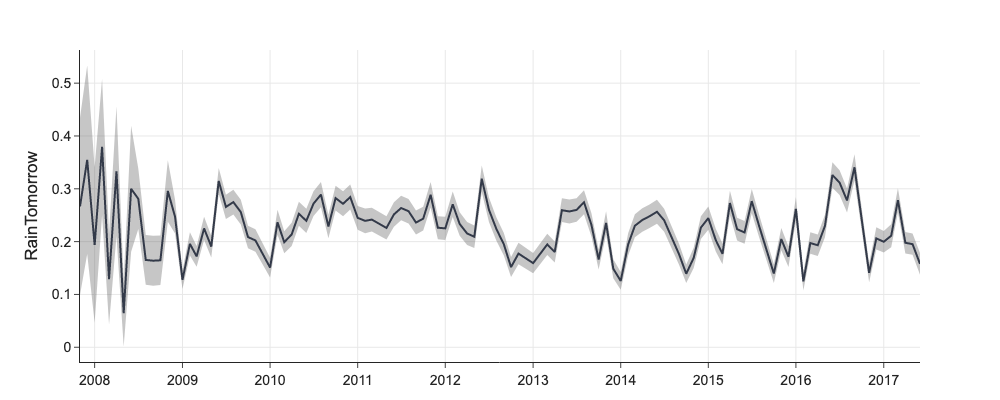
d = mlp.eda_categorical(df[['RainTomorrow', 'YearMonth']], 'RainTomorrow', max_categorical_values=0)
fig = go.Figure([
go.Scatter(name='RainTomorrow', x=d['value'], y=d['mean'], mode='lines', showlegend=False),
go.Scatter(x=d['value'], y=d['mean']+d['ci'], mode='lines', line=dict(width=0), showlegend=False),
go.Scatter(x=d['value'], y=d['mean']-d['ci'], mode='lines', line=dict(width=0), showlegend=False,
fillcolor='rgba(68, 68, 68, 0.3)', fill='tonexty')
])
fig.update_layout(title='', yaxis_title='RainTomorrow')
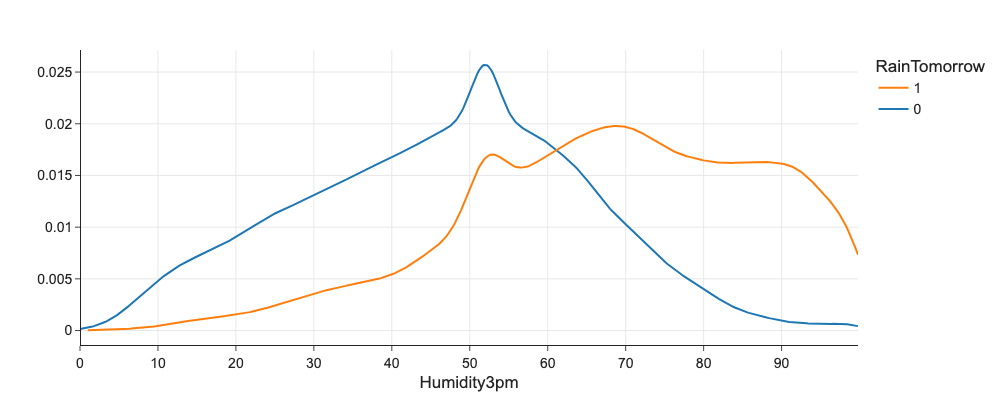
Numerical Features¶
We check univariate distribution of numerical feature against target variable using histograms or eg. kernel density plots. If distributions are distinct, we have a good predictive feature.
# Does Humidity3pm correlates with RainTomorrow?
import plotly.figure_factory as ff
fig = ff.create_distplot(
[df[df.RainTomorrow == 0]['Humidity3pm'], df[df.RainTomorrow == 1]['Humidity3pm']],
['0', '1'],
bin_size=1,
show_hist=False,
show_rug=False,
show_curve=True,
)
fig.update_layout(xaxis_title='Humidity3pm', legend_title='RainTomorrow')
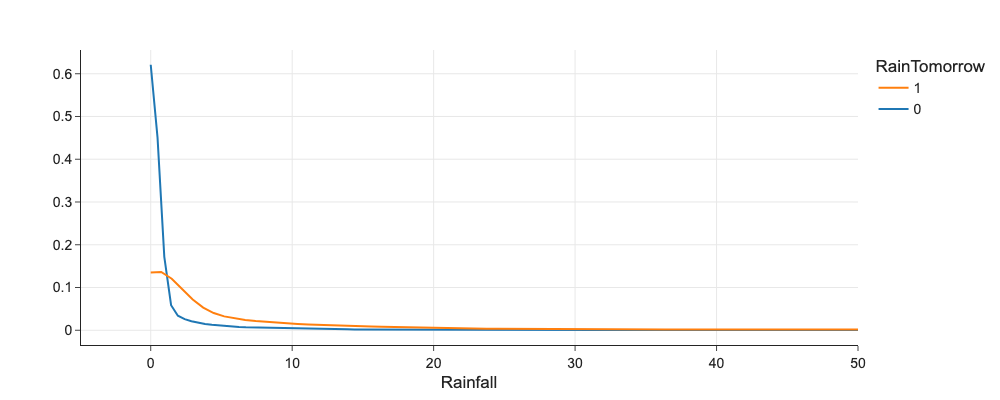
# Does Humidity3pm correlates with RainTomorrow?
import plotly.figure_factory as ff
fig = ff.create_distplot(
[df[df.RainTomorrow == 0]['Rainfall'], df[df.RainTomorrow == 1]['Rainfall']],
['0', '1'],
bin_size=1,
show_hist=False,
show_rug=False,
show_curve=True,
)
fig.update_layout(xaxis_title='Rainfall', legend_title='RainTomorrow', xaxis_range=[-5,50])
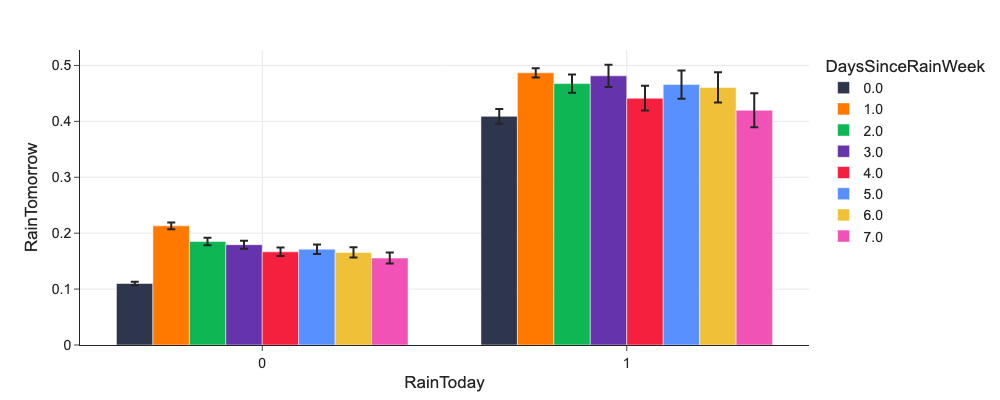
Categorical vs. Categorical¶
We can use grouped bar charts to check how are combinations of two categorical features represented in target feature.
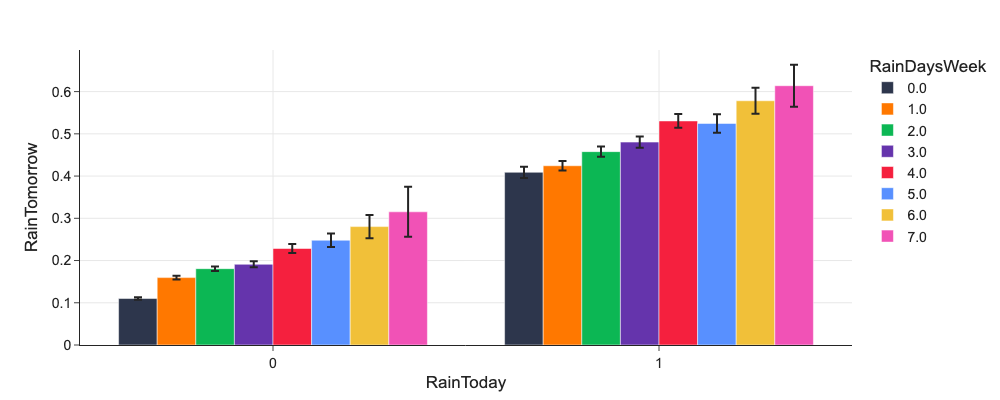
# Do RainToday and DaysSinceRainWeek or RainDaysWeek influence RainTomorrow?
d = mlp.eda_grouped(df, 'RainTomorrow', ['RainToday', 'DaysSinceRainWeek'])
d.DaysSinceRainWeek = d.DaysSinceRainWeek.astype('category')
px.bar(d, x='RainToday', y='mean', color='DaysSinceRainWeek', error_y='ci', barmode='group', labels={'mean': 'RainTomorrow'})
# Do RainToday and DaysSinceRainWeek or RainDaysWeek influence RainTomorrow?
d = mlp.eda_grouped(df, 'RainTomorrow', ['RainToday', 'RainDaysWeek'])
d.RainDaysWeek = d.RainDaysWeek.astype('category')
px.bar(d, x='RainToday', y='mean', color='RainDaysWeek', error_y='ci', barmode='group', labels={'mean': 'RainTomorrow'})
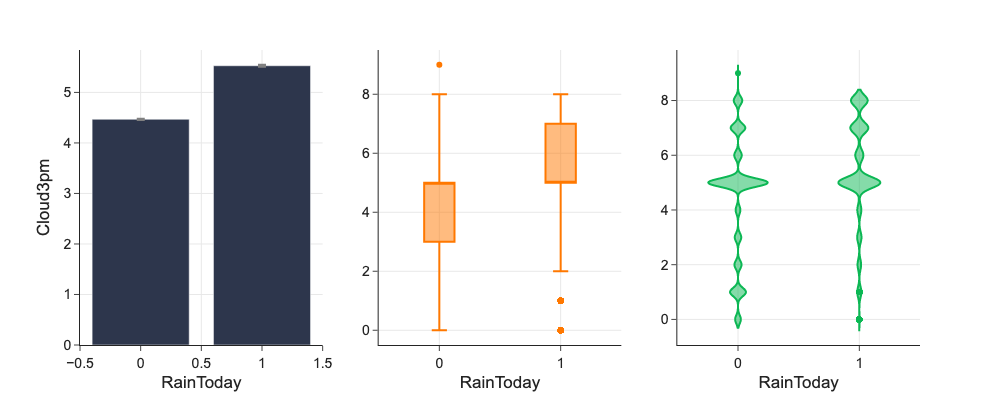
Categorical vs. Numerical¶
We can use bar charts or violin plots groupped by target feature to check distribution of some numerical feature against values of categorical feature.
Bars give us point estimate of the mean value.
Box plots give us spread, quartiles, and outliers.
Violin plots give us pdf.
# More details about numerical feature distribution
from plotly.subplots import make_subplots
fig = make_subplots(rows=1, cols=3, shared_yaxes=False)
d = mlp.eda_categorical(df[['RainToday', 'Cloud3pm']], 'Cloud3pm')
fig.add_trace(
go.Bar(x=d['value'], y=d['mean'], error_y=dict(type='data', array=d['ci'], color='grey')),
row=1, col=1
)
fig.add_trace(
go.Box(x=df['RainToday'], y=df['Cloud3pm']),
row=1, col=2
)
fig.add_trace(
go.Violin(x=df['RainToday'], y=df['Cloud3pm'], meanline_visible=True),
row=1, col=3
)
fig.update_xaxes(title_text="RainToday", row=1, col=1)
fig.update_xaxes(title_text="RainToday", row=1, col=2)
fig.update_xaxes(title_text="RainToday", row=1, col=3)
fig.update_yaxes(title_text="Cloud3pm", row=1, col=1)
fig.update_traces(meanline_visible=True, row=1, col=3)
fig.update_layout(showlegend=False)
fig.show()
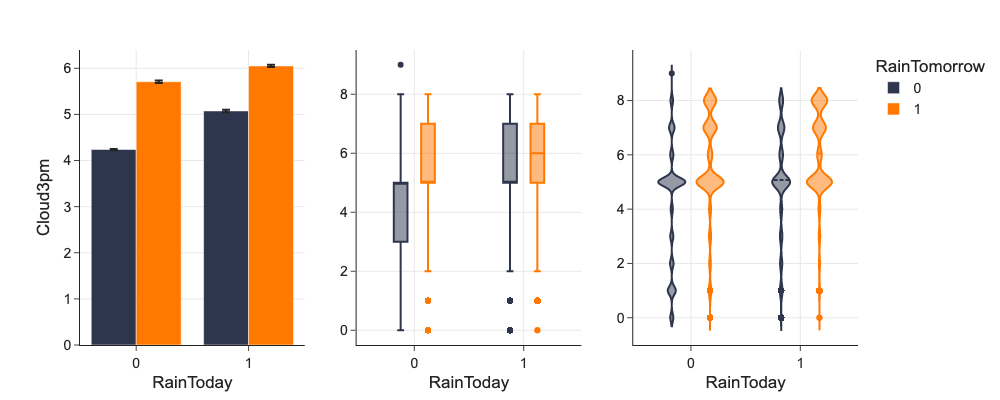
To check impact of category and numerical feature to target feature, we can use color by target feature.
# Going deeper and using color
d = mlp.eda_grouped(df[['RainToday', 'RainTomorrow', 'Cloud3pm']], 'Cloud3pm', ['RainToday', 'RainTomorrow'])
fig = make_subplots(rows=1, cols=3, shared_yaxes=False)
fig.add_trace(
go.Bar(name='0',
legendgroup='a',
marker={'color': '#2D364C'},
x=d.RainToday.unique(), y=d[d.RainTomorrow == 0]['mean'], error_y={'array': d[d.RainTomorrow == 0]['ci']}
),
1, 1
)
fig.add_trace(
go.Bar(name='1',
legendgroup='a',
marker={'color': '#FF7800'},
x=d.RainToday.unique(), y=d[d.RainTomorrow == 1]['mean'], error_y={'array': d[d.RainTomorrow == 1]['ci']}),
1, 1
)
fig.add_trace(
go.Box(name='0',
legendgroup='a', showlegend=False,
marker={'color': '#2D364C'},
x=df[df.RainTomorrow == 0]['RainToday'], y=df[df.RainTomorrow == 0]['Cloud3pm']
),
1, 2
)
fig.add_trace(
go.Box(name='1',
legendgroup='a', showlegend=False,
marker={'color': '#FF7800'},
x=df[df.RainTomorrow == 1]['RainToday'], y=df[df.RainTomorrow == 1]['Cloud3pm']
),
1, 2
)
fig.add_trace(
go.Violin(name='0',
legendgroup='a', showlegend=False,
marker={'color': '#2D364C'},
x=df[df.RainTomorrow == 0]['RainToday'], y=df[df.RainTomorrow == 0]['Cloud3pm'], meanline_visible=True),
row=1, col=3
)
fig.add_trace(
go.Violin(name='1',
legendgroup='a', showlegend=False,
marker={'color': '#FF7800'},
x=df[df.RainTomorrow == 1]['RainToday'], y=df[df.RainTomorrow == 1]['Cloud3pm'], meanline_visible=True),
row=1, col=3
)
fig.update_layout(
boxmode='group', barmode='group', violinmode='group', legend={'title': 'RainTomorrow'}
)
fig.update_xaxes(title_text="RainToday", row=1, col=1)
fig.update_xaxes(title_text="RainToday", row=1, col=2)
fig.update_xaxes(title_text="RainToday", row=1, col=3)
fig.update_yaxes(title_text="Cloud3pm", row=1, col=1)
fig.update_traces(meanline_visible=True, row=1, col=3)
fig
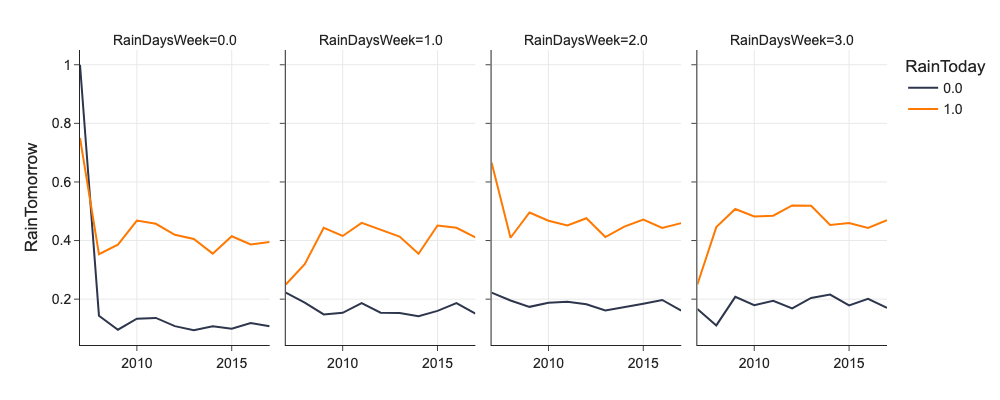
Facets¶
We can facet plots by values of some categorical features to investigate interactions of upto 4 features agaist target feature. We generally put target variable on y axis, and use x, columns, rows, and hue for upto 4 explanatory features.
# facets
d = mlp.eda_grouped(df[['RainDaysWeek', 'RainTomorrow', 'RainToday', 'Year']], 'RainTomorrow', ['RainDaysWeek', 'RainToday', 'Year'])
d = d[(d.RainDaysWeek <= 3)]
d.RainDaysWeek = d.RainDaysWeek.astype('category')
d.RainToday = d.RainToday.astype('category')
px.line(d, x='Year', y='mean', color='RainToday', facet_col='RainDaysWeek', labels={'mean': 'RainTomorrow', 'Year': ''})
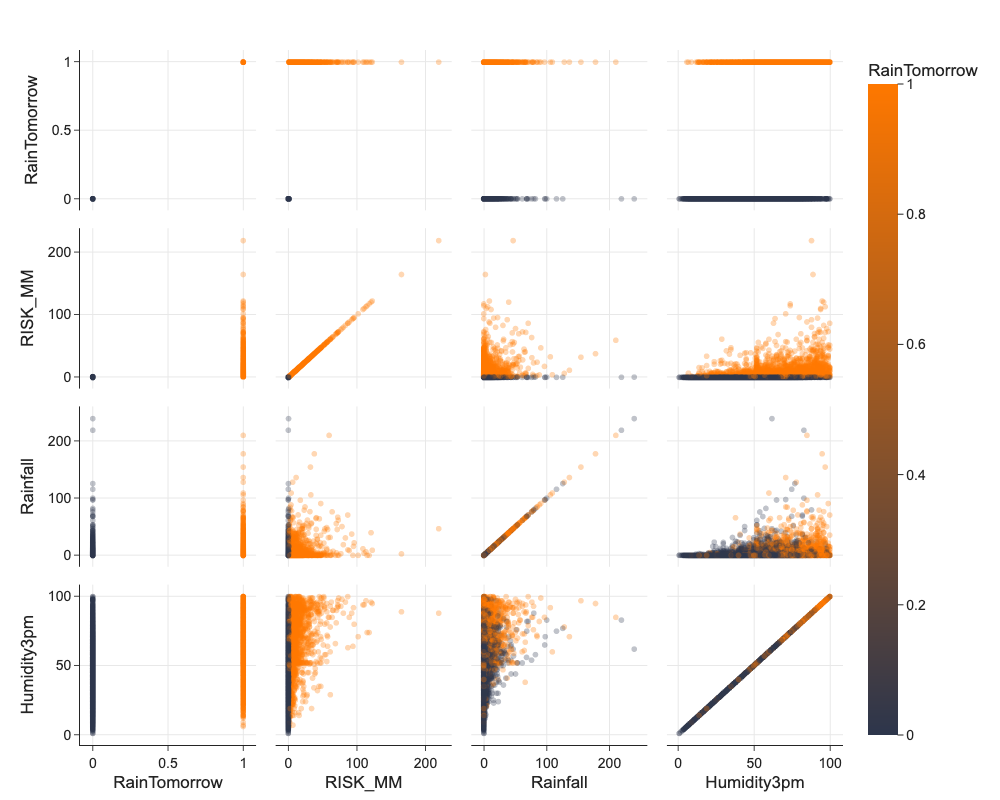
Interactions of Pairs of Features Using Pair Plots or Scatter Plots¶
We can use Seaborn pairplot to have analyze interactions and distributions of many features at once. These plots need time to plot and are best used printed :)
# beware this takes long minutes to calculate and display
vars = ['RainTomorrow', 'RISK_MM', 'Rainfall', 'Humidity3pm']
png_renderer.height = 800
px.scatter_matrix(df.sample(10000), color='RainTomorrow', dimensions=vars, opacity=0.3)

Covariance¶
It is not sometimes straightforward to inspect relationshipe between features visually when there are hundreds or thousands of features. Covariance measures how similarly values of two features A and B behave in relation to their respective means.
Positive values of covariance signal that positive relationship, negative values signal negative relationship and values around \(0\) signal no relationship. Covariance values are in units of features, it makes no sense to compare pairs of features using it.
Correlation¶
Normalized covariance is called correlation and it is in interval \([-1,1]\).
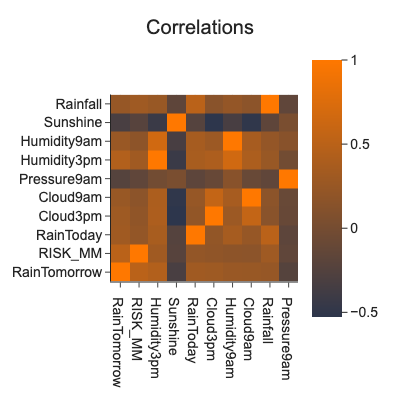
Correlation captures only linear relationshipes between features, there could be more complex relationships like quadratical that we do not discover using correlation. When we calculate correlations for all features, we get correlation matrix good for visual inspection.
# correlations
corr = df.corr()
top_corrs = corr['RainTomorrow'].abs().sort_values(ascending=False)[:10].index
d = corr.loc[corr.index.isin(top_corrs)][top_corrs]
png_renderer.height = 400
png_renderer.width = 400
px.imshow(d, title='Correlations')
Correlation is not causation:
Swallows cause hot weather, spinning windmills cause wind, playing basketball causes people to be tall.
Confounding feature (hidden 3rd factor) eg. young children sleeping with night-light turned on developing short-sightedness
Causation can be only proved by random experiment.
Features with strong correlation with the target are suspicious and worth investigation. It could be a hint of hidden leaks like time traveling in features etc.
Data Preparation¶
Normalization¶
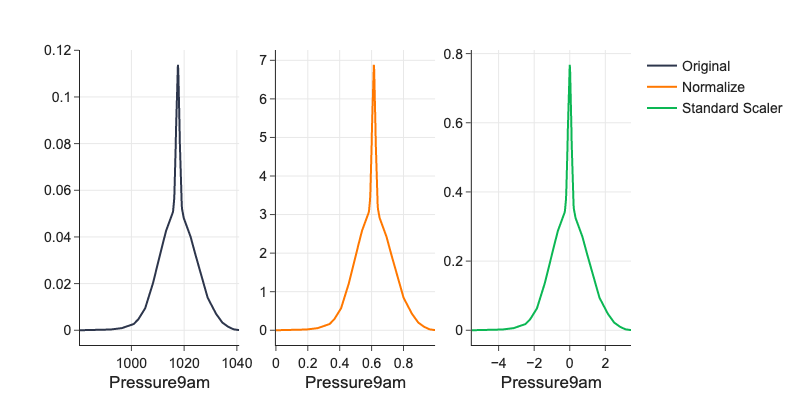
Features usually vary a lot in their ranges. This is a problem to any ML algorithm using distances like k-nearest neighbors, to PCA which works with variance which is high for high-magnitude features, or to deep learning where it slows down gradient descend or even disables its convergence completely. For example if feature \(x \in [0, 5]\) and feature \(z \in [0, 1000]\) then increase by \(1\) in \(x\) and \(z\) means something different and we cannot compare it.
Normalize into \([0, 1]\) by
Standardize by
# examples of normalization
from sklearn.preprocessing import StandardScaler, normalize
d = df['Pressure9am'].dropna()
ds = StandardScaler().fit_transform(d.values.reshape(-1, 1))
dn = (d - d.min()) / (d.max() - d.min())
png_renderer.width = 800
fig = make_subplots(rows=1, cols=3, shared_xaxes=False, shared_yaxes=False)
fx1 = ff.create_distplot(
[d, dn, ds[:,0]],
['0', '1', '2'],
curve_type='kde',
bin_size=1,
show_hist=False,
show_rug=False,
show_curve=True
)
fig.add_trace(go.Scatter(name='Original', x=fx1.data[0]['x'], y=fx1.data[0]['y']), 1,1)
fig.add_trace(go.Scatter(name='Normalize', x=fx1.data[1]['x'], y=fx1.data[1]['y']), 1,2)
fig.add_trace(go.Scatter(name='Standard Scaler', x=fx1.data[2]['x'], y=fx1.data[2]['y']), 1,3)
fig.update_xaxes(title_text="Pressure9am", row=1, col=1)
fig.update_xaxes(title_text="Pressure9am", row=1, col=2)
fig.update_xaxes(title_text="Pressure9am", row=1, col=3)
Binning¶
Binning converts continous feature into categorical one for better interpretation of the model, better generalization, and preventing overfitting. Eg. latitude have impact on housing price, but not linear, we could bin latitude to make it categorical.
Machine Learning Crash Course, Google
We can:
Create equally-wide bins - does not work well for uni-modal distributions because few bins will have many samples and many bins will cover long tail with few samples each.
Create equal-frequency bins - more appropriate for uni-modal but is less explainable.
Binning handles outliers automatically.
For categorical data, it might be benefitial to squash low-frequent values under ‘Other’, you do not want necesirily to end up with sparse feature matrices.
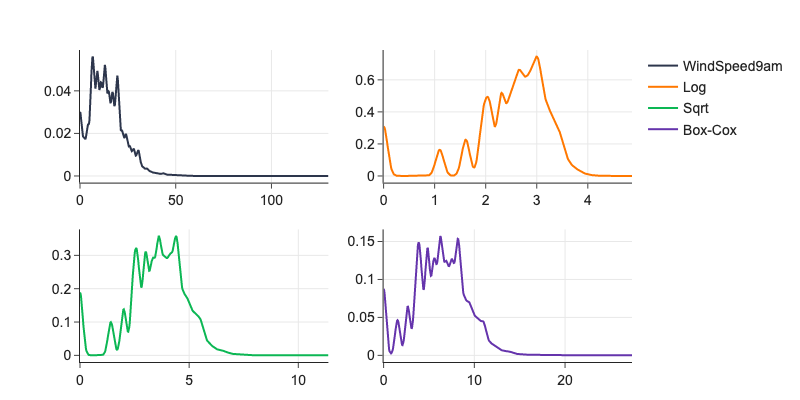
Fixing Skewness¶
Taking log of values makes exponential or “long-tail” distributions more normal.
Logarithm makes comparisons of values of many orders of magnitudes possible eg. change from 1 to 10 is the same as change from 10 000 to 100 000 (consider eg. value of money).
In many datasets, magnitude order of the data changes within the range of the data.
It handles outliers.
Box-cox¶
Box-cox (power) transformation is generalization of taking \(log\) of features. Box-cox transform first fits \(\lambda\) using maximum log-likelihood method to feature values.
# example of long-tailed distribution
d = df['WindSpeed9am'].dropna()
l, lmbda = st.boxcox(d+1)
fig = make_subplots(rows=2, cols=2, shared_xaxes=False, shared_yaxes=False)
fx1 = ff.create_distplot(
[d, np.log(d+1), np.sqrt(d), st.boxcox(d+1, lmbda=lmbda)],
['0', '1', '2', '3'],
curve_type='kde',
bin_size=1,
show_hist=False,
show_rug=False,
show_curve=True
)
fig.add_trace(go.Scatter(name='WindSpeed9am', x=fx1.data[0]['x'], y=fx1.data[0]['y']), 1,1)
fig.add_trace(go.Scatter(name='Log', x=fx1.data[1]['x'], y=fx1.data[1]['y']), 1,2)
fig.add_trace(go.Scatter(name='Sqrt', x=fx1.data[2]['x'], y=fx1.data[2]['y']), 2,1)
fig.add_trace(go.Scatter(name='Box-Cox', x=fx1.data[3]['x'], y=fx1.data[3]['y']), 2,2)
Dimensionality Reduction¶
High-dimensional datasets can be very difficult to visualize. While data in two or three dimensions can be plotted to show the inherent structure of the data, equivalent high-dimensional plots are much less intuitive. To aid visualization of the structure of a dataset, the dimension must be reduced in some way.
The simplest way to accomplish this dimensionality reduction is by taking a random projection of the data. Though this allows some degree of visualization of the data structure, the randomness of the choice leaves much to be desired. In a random projection, it is likely that the more interesting structure within the data will be lost. Link
Scikit-learn Manifold Learning
Linear decomposition frameworks like principal component analysis (PCA) and non-linear manifold learning (t-SNE) can make these projections possible and informative. Manifold learning is not that intuitive compared to linear decomposition and needs good parameter tuning (see eg. nice visualization building some intuition in How to Use t-SNE Effectively).
Distill.pub, How to Use t-SNE Effectively
# beware, this takes about 30 minutes to compute
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
features = []
features += [('Location', OneHotEncoder(drop='first', sparse=False), ['Location'])]
features += [('YearMonth', OneHotEncoder(drop='first', sparse=False, categories='auto'), ['YearMonth'])]
features += [('Humidity3pm', SimpleImputer(strategy='mean'), ['Humidity3pm'])]
pipeline_pca = Pipeline([('ct', ColumnTransformer(features)),
('sca', StandardScaler()),
('pca', PCA(n_components=2))
])
pipeline_tsne = Pipeline([('ct', ColumnTransformer(features)),
('sca', StandardScaler()),
('tsne', TSNE(n_components=2, perplexity=50)),
])
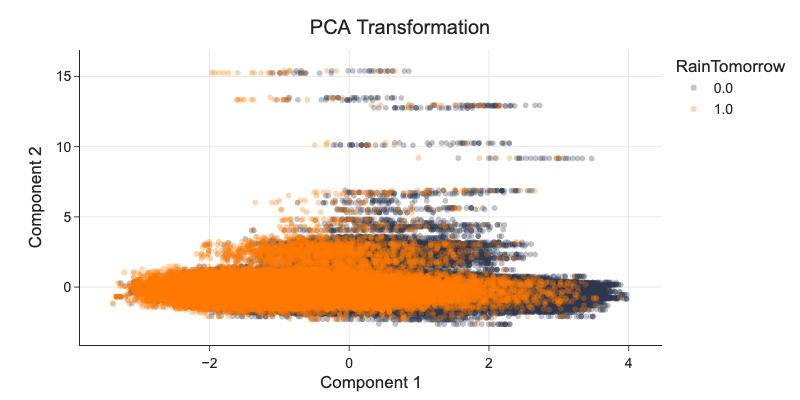
o_pca = np.hstack((pipeline_pca.fit_transform(df), df['RainTomorrow'].values.reshape(-1, 1)))
d_pca = pd.DataFrame(o_pca, columns=['Component 1', 'Component 2', 'RainTomorrow'])
o_tsne = np.hstack((pipeline_tsne.fit_transform(df), df['RainTomorrow'].values.reshape(-1, 1)))
d_tsne = pd.DataFrame(o_tsne, columns=['Component 1', 'Component 2', 'RainTomorrow'])
d_pca.RainTomorrow = d_pca.RainTomorrow.astype('category')
fig = px.scatter(d_pca, x='Component 1', y='Component 2', color='RainTomorrow', title='PCA Transformation')
fig.update_traces(marker_opacity=0.3)
d_tsne.RainTomorrow = d_tsne.RainTomorrow.astype('category')
fig = px.scatter(x=d_tsne['Component 1'], y=d_tsne['Component 2'], color=d_tsne['RainTomorrow'], title='t-SNE Transformation')
fig.update_traces(marker_opacity=0.3)
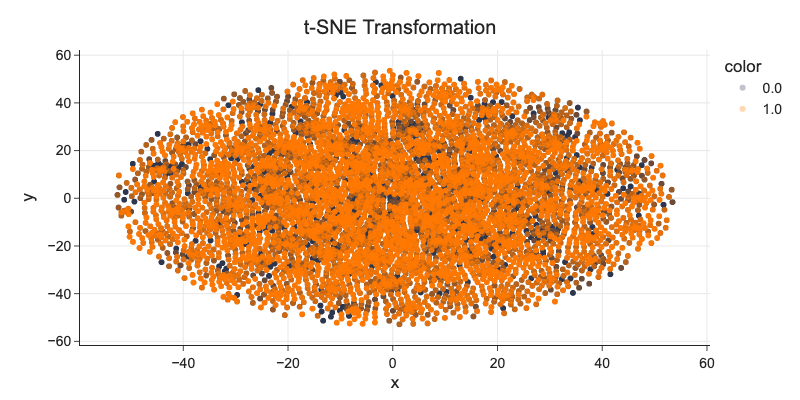
Handling Class Imbalance¶
In a case where we have 2% to 98% imbalanced dataset, always predicting majority class gives us model with 98% accuracy.
Imbalanced datasets are common. Accuracy paradox tells us that accuracy defined as is not a good metric. Accuracy is defined as number of correctly classified instances / all instances.
Strategies:
Use penalized models - model pays more when missclassifying minority class.
Under-sample majority class if you have many data.
Over-sample minority class if you do not have enough data.
Generate synthetic samples using eg. imblearn’s SMOTE or Synthetic Minority Oversampling Technique.
Use precission, recall, f1-score to evaluate model, they do not have accuracy paradox.
Change model, eg. random forests are not that sensitive to imbalanced datasets.
When doing over-sampling, always sample after splitting the dataset into training and testing (, validation) datasets.
Over-sampling Using SMOTE and ADASYN Techniques
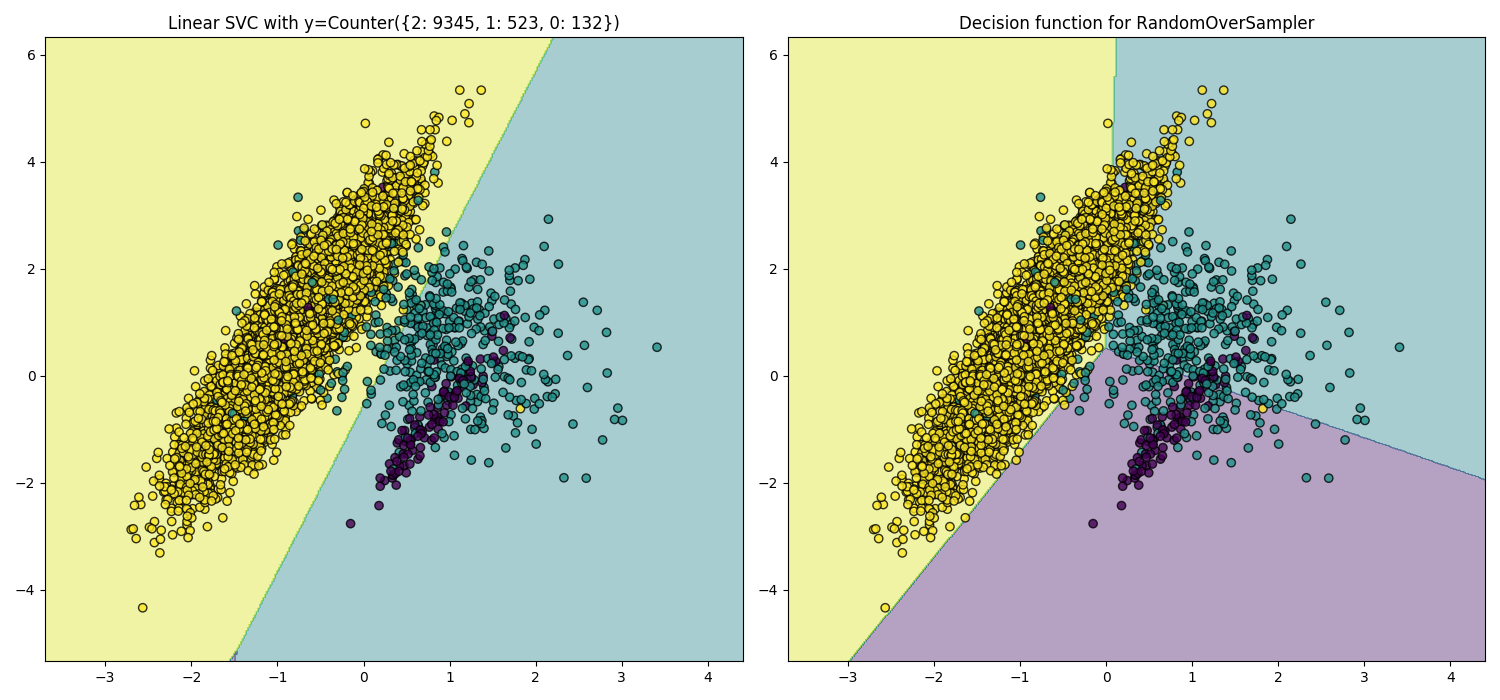
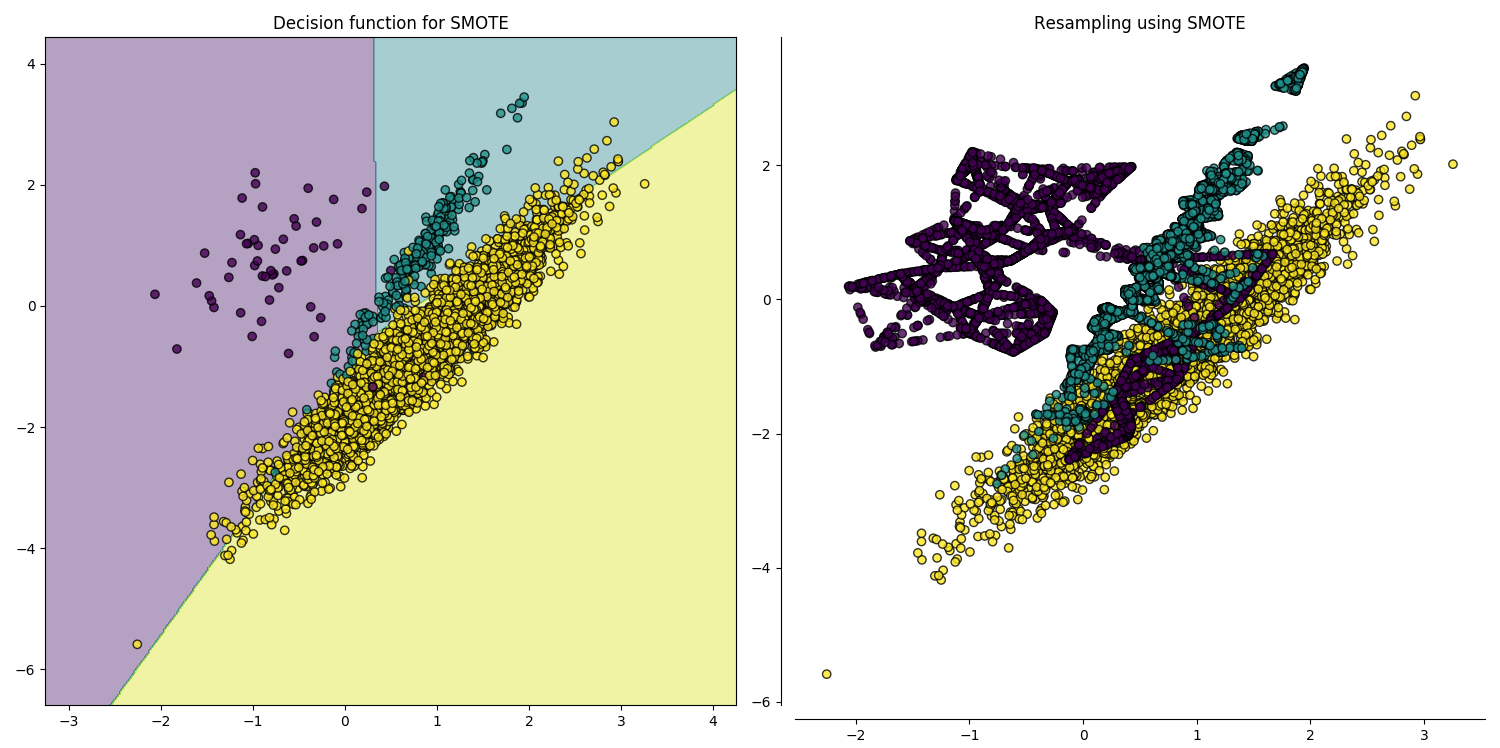
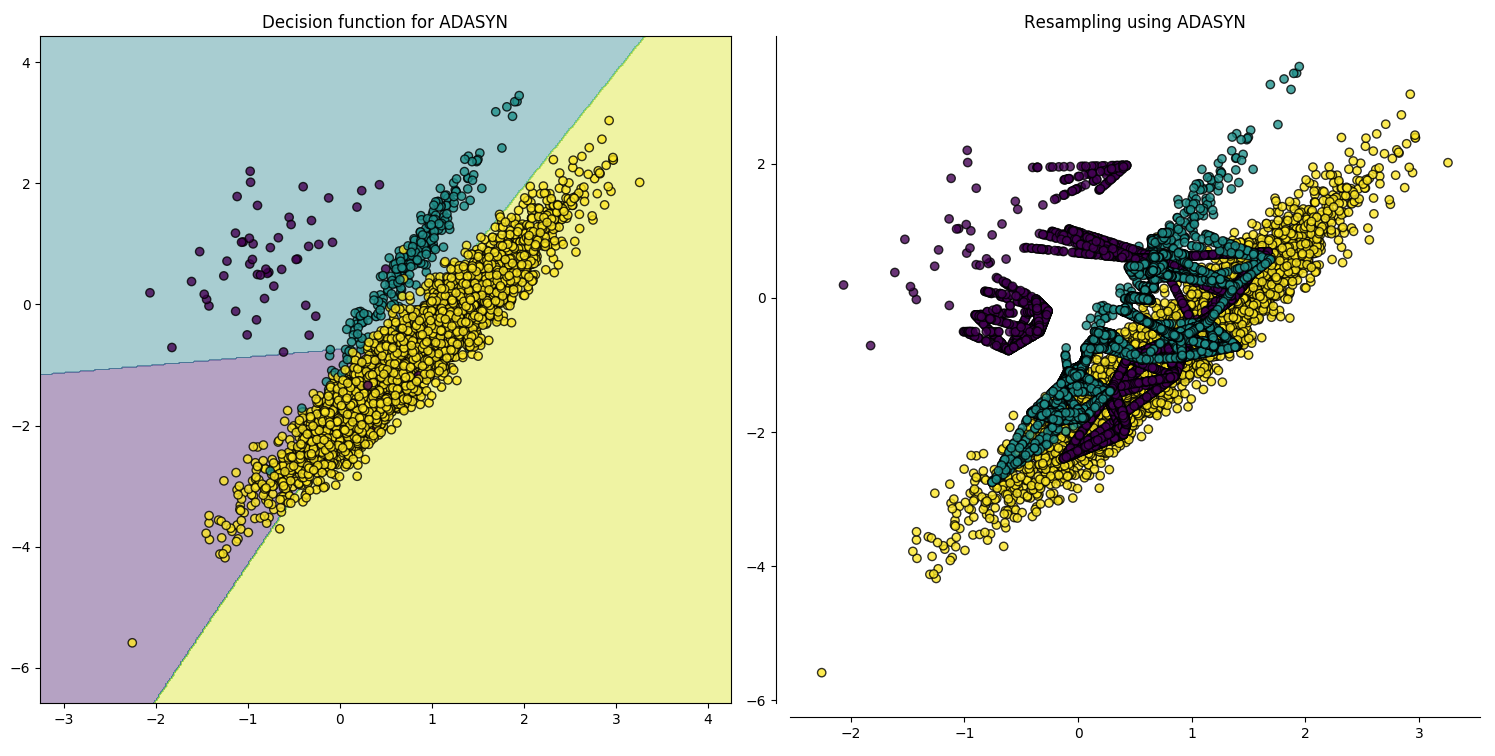
Decision boundaries.
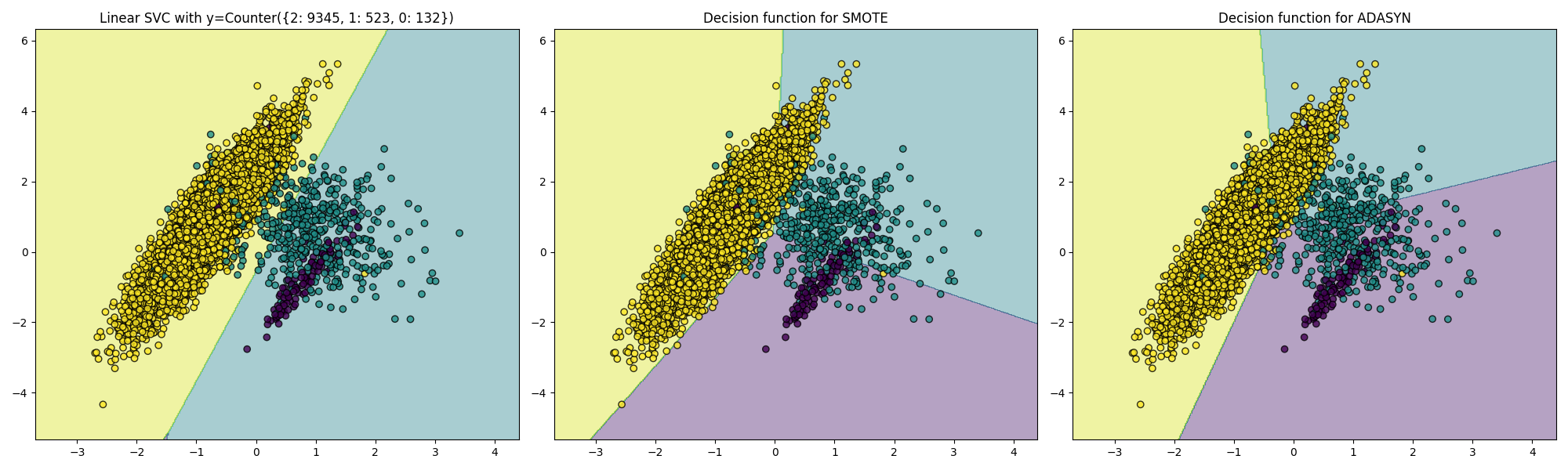
Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning.
Our dataset is slightly imbalanced, we will see how different algorithms handle this in the next lesson.
df['RainTomorrow'].value_counts()
0 110316
1 31877
Name: RainTomorrow, dtype: int64
The First Model¶
Let’s try to combine all we learned into one dataset and let’s use some simple model on it.
We first encode categorical feature using OHE.
numeric_columns = list(df.select_dtypes(['float64']).columns) + list(df.select_dtypes(['int64']).columns)
numeric_columns.remove('RainTomorrow')
numeric_columns.remove('Id')
ohe = OneHotEncoder(drop='first', sparse=False).fit_transform(df[['WindDir9am', 'WindDir3pm', 'WindGustDir', 'Location', 'YearMonth']])
train = np.hstack([ohe, df[numeric_columns + ['RainTomorrow']]])
We keep 30% of samples out of sight of the model to have a good way to evaluate model performance.
from sklearn.model_selection import train_test_split
train, test = train_test_split(train, test_size=0.3)
x_train = train[:, :-1]
y_train = train[:, -1]
x_test = test[:, :-1]
y_test = test[:, -1]
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(x_train, y_train);
from sklearn.metrics import classification_report
print('Classifition report on testing dataset')
print(classification_report(y_test, model.predict(x_test)))
Classifition report on testing dataset
precision recall f1-score support
0.0 1.00 1.00 1.00 33133
1.0 1.00 1.00 1.00 9525
accuracy 1.00 42658
macro avg 1.00 1.00 1.00 42658
weighted avg 1.00 1.00 1.00 42658
It looks too good to be true!¶
Do you know what the problem could be?
Resources¶
John D. Kelleher et al., Fundamentals of Machine Learning for Predicitve Data Analytics
Sebastian Raschka, Python Machine Learning