Experimenation¶
Having two comparable models, we want to answer simple question - is model A or B doing better? It turns out that answering this simple question is quite complex.
# youtube
from IPython.display import YouTubeVideo
YouTubeVideo('-kjRL-Q-KBc', start=55, width=600, height=400)

Online Controlled Experiments¶
Online controlled experiments, A/B tests or simply experiments, are widely used by data-driven companies to evaluate the impact of change and are the only data-driven approach to prove causality.

Sample of real users, not WEIRD (Western, Educated, Industrialized, Rich, and Democratic).
Experiment execution:
Users are randomly assigned to one of the two variants: Control (A) or Treatment (B).
Control is usually existing system while Treatment is the system with the new feature \(X\) to test.
Users’ interactions with the system are recorded.
We calculate metrics from recorded data.
If the experiment has been designed and executed correctly, the only thing consistently different between the two variants is feature \(X\). All external factors are eliminated by being evenly distributed among Control and Treatment. We can hypothesize that any difference in metrics between the two variants can be attributed to either feature \(X\) or to due to a change resulted from random assigment of users to variants. The later is ruled out (probalistically) using statistical tests. This establishes a causal relationship between the feature change \(X\) and changes in user behavior. In S. Gupta, R. Kohavi, et al. Top Challenges from the first Practical Online Controlled Experiments Summit
Why A/B Tests?¶
Because assessing the value of novel ideas is hard.
Correlation and Causation¶
Bloodletting effect of having calming effects on patients let doctors practice it for 2000 years.
 Wikipedia
Wikipedia

Learnings¶
To have a great idea, have a lot of them. (Thomas Edison)
If you have to kiss a lot of frogs, to find a prince, find more frogs and kiss them faster and faster. (Mike Moran, Do it Wrong Quickly)
 |
 |
HiPPO¶

If we have data, let’s look at data. If all we have are opinions, let’s go with mine. (Jim Barksdale - former CEO of Netscape). Link.
# import some basic libraries to do analysis and ML
import pandas as pd
import numpy as np
import sklearn as sk
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import scipy.stats as st
import seaborn as sns
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
# Visualization details
mpl.style.use('ggplot')
sns.set_style('white')
pylab.rcParams['figure.figsize'] = 12,8
Statistics at Heart¶
Experiments and their evaluation is a work with uncertainity that requires some mathematics so we can talk about it precisly :)
Let’s use an experiment measuring click through rate CTR (defined as clicks/views) of some button on some website. Control variant A (current default) uses green color, threatment variant B (challenger) uses red button. We ran randomized experiment on users of our website with following results
What Variant to Choose?¶
Variant |
Views |
Clicks |
CTR |
Relative Difference |
|---|---|---|---|---|
A |
1,000 |
100 |
10% |
— |
B |
1,000 |
110 |
11% |
+10% |
Before we decided to run such test, we agreed on stopping it when both variants reach 1,000 views. We can’t run this experiment any longer because it takes too long to get that many views. Our question to answer is if variant B is better than variant A. This is all information we have and we have to determine if we trust that B is better than A.
We work with a sample of 1,000 views per variant and want to reason about whole populations of views (users, …) in A and B. CTR of 10% (11%) are the most likely estimates of population CTR given the data we have. But the real situation is little bit more complicated. True population CTRs can be anywhere around our estimates.
Probability distribution of true population CTRs.
# estimations
N = 100000
a = st.beta(100, 1000 - 100)
b = st.beta(110, 1000 - 110)
a_rvs = a.rvs(N)
b_rvs = b.rvs(N)
fig, ax = plt.subplots(figsize=(7, 5))
cs = sns.color_palette("husl", 2)
sns.kdeplot(a_rvs, bw='silverman', legend=True, ax=ax, label='A', linewidth=4, color=cs[0]);
ax.axvline(np.mean(a_rvs), 1., 0., c=cs[0], linestyle='dashed', alpha=.4, label='A Mean', linewidth=3)
sns.kdeplot(b_rvs, bw='silverman', legend=True, ax=ax, label='B', linewidth=4, color=cs[1]);
ax.axvline(np.mean(b_rvs), 1., 0., c=cs[1], linestyle='dashed', alpha=.4, label='B Mean', linewidth=3)
ax.set_title('Estimation of CTR')
ax.set_xlabel('CTR');
ax.set_ylabel('Density')
ax.legend()
ax.grid();
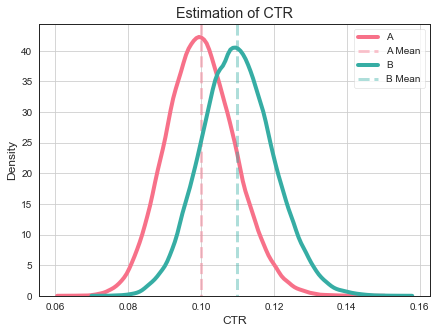
It can easily happen that true CTR of variant B is below true CTR of variant A despite measuring otherwise.
# where could true population means be?
fig, ax = plt.subplots(figsize=(7, 5))
cs = sns.color_palette("husl", 2)
sns.kdeplot(a_rvs, bw='silverman', legend=True, ax=ax, label='A', linewidth=4, color=cs[0]);
ax.axvline(np.mean(a_rvs), 1., 0., c=cs[0], linestyle='dashed', alpha=.4, label='A Mean', linewidth=3)
sns.kdeplot(b_rvs, bw='silverman', legend=True, ax=ax, label='B', linewidth=4, color=cs[1]);
ax.axvline(np.mean(b_rvs), 1., 0., c=cs[1], linestyle='dashed', alpha=.4, label='B Mean', linewidth=3)
ax.set_title('Estimation of CTR')
ax.set_xlabel('CTR');
ax.set_ylabel('Density')
ax.legend()
ax.grid();
ax.arrow(0.11, 10, 0, -10, length_includes_head=True, width=.005, head_length=2, head_width=.01, overhang=0, color=cs[0], shape='full', zorder=10);
ax.arrow(0.09, 10, 0, -10, length_includes_head=True, width=.005, head_length=2, head_width=.01, overhang=0, color=cs[1], shape='full', zorder=10);
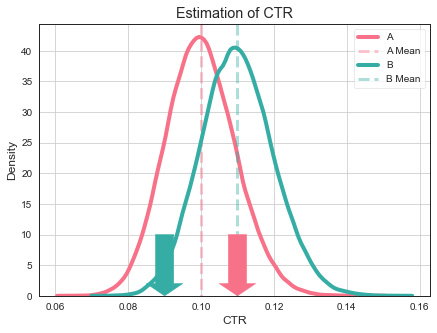
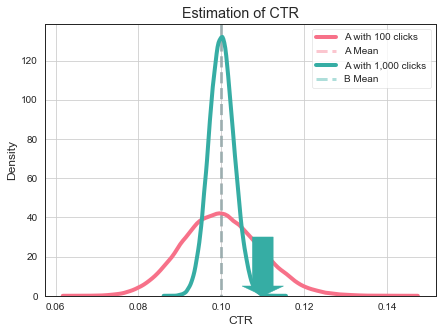
What to do, do having more data help in this case? Yes, having more data makes our estimate more accurate. So it is very unlikely that CTR of variant A to be close to 0.11.
# effect of more samples in the experiment
N = 100000
a = st.beta(100, 1000 - 100)
b = st.beta(1000, 10000 - 1000)
a_rvs = a.rvs(N)
b_rvs = b.rvs(N)
fig, ax = plt.subplots(figsize=(7, 5))
cs = sns.color_palette("husl", 2)
sns.kdeplot(a_rvs, bw='silverman', legend=True, ax=ax, label='A with 100 clicks', linewidth=4, color=cs[0]);
ax.axvline(np.mean(a_rvs), 1., 0., c=cs[0], linestyle='dashed', alpha=.4, label='A Mean', linewidth=3)
sns.kdeplot(b_rvs, bw='silverman', legend=True, ax=ax, label='A with 1,000 clicks', linewidth=4, color=cs[1]);
ax.axvline(np.mean(b_rvs), 1., 0., c=cs[1], linestyle='dashed', alpha=.4, label='B Mean', linewidth=3)
ax.set_title('Estimation of CTR')
ax.set_xlabel('CTR');
ax.set_ylabel('Density')
ax.legend()
ax.grid();
ax.arrow(0.11, 30, 0, -30, length_includes_head=True, width=.005, head_length=5, head_width=.01, overhang=0, color=cs[1], shape='full', zorder=10);
Null Hypothesis Significance Testing¶
Null hypothesis significance testing is common approach to deal with this uncertainties.
NHST decides if a null hypothesis can be rejected given obtained data.
Examples of null and alternative hypothesis:
\(H_0\): A coin is fair.
Meaning we can expect equal number of heads and tails from \(N\) tosses of the coin.
\(H_1\): A coin is biased towards heads or tails.
\(H_0\): CTRs of variants A and B are equal.
\(H_1\): There’s difference between CTR in A and B.
Sampling Distribution¶
# sampling distributions
import scipy.stats as st
x1 = st.norm.rvs(size=1000)
y1 = st.norm.rvs(size=1000)
x2 = st.norm.rvs(scale=2, size=1000)
y2 = st.norm.rvs(scale=2, size=1000)
fig, ax = plt.subplots(figsize=(6, 6));
# ax = axx[0]
# ax.scatter(x1, y1, marker='o', alpha=.4);
# ax.scatter([1.5], [0], marker='o', color='g', lw=10)
# c = plt.Circle((0, 0), radius=1.5, color='g', fill=False, lw=3);
# ax.add_artist(c);
# ax.arrow(1.5, 0., 1.0, 0., width=.05, head_width=.2, overhang=0.1, color='k');
# ax.arrow(2.5, 0., -0.7, 0., width=.05, head_width=.2, overhang=0.1, color='k', shape='full');
# ax.arrow(1.5, 2., 0, -1.6, width=.05, head_width=.2, overhang=0.1, color='k', shape='full');
# ax.text(2, .3, 'Extreme values', fontsize=18);
# ax.text(1.5, 2, 'Actual Outcome', fontsize=18);
# ax.set_xlim((-7, 7));
# ax.set_ylim((-7, 7));
# ax.set_title('Sampling Distribution for Null Hypothesis H');
# ax.grid()
ax.scatter(x2, y2, marker='o', alpha=.4);
ax.scatter([2.5], [0], marker='o', color='r', lw=10)
c = plt.Circle((0, 0), radius=2.5, color='r', fill=False, lw=3);
ax.add_artist(c);
ax.arrow(2.5, 0., 3., 0., width=.05, head_width=.3, overhang=0.1, color='k', shape='full');
ax.arrow(4.5, 0., -1.6, 0., width=.05, head_width=.3, overhang=0.1, color='k', shape='full');
ax.arrow(2.5, 2., 0, -1.6, width=.05, head_width=.3, overhang=0.1, color='k', shape='full');
ax.text(2.5, 2, 'Actual Outcome', fontsize=18);
ax.text(2.7, .3, 'Extreme values', fontsize=18);
ax.set_xlim((-7, 8.5));
ax.set_ylim((-7, 8.5));
ax.set_title('Sampling Distribution for Null Hypothesis H');
ax.grid()
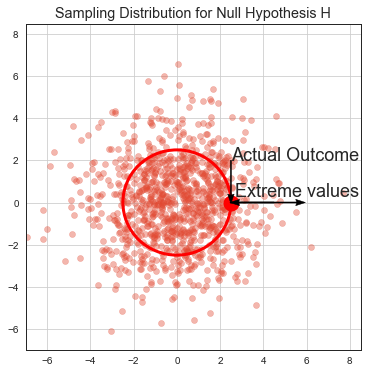
Let’s assume our null hypothesis is valid. If we ran the same experiment many times, we get many point estimates \(\hat{\mu}\) of population metric mean \(\mu\) (eg. CTR). These estimates are normally distributed because of a Central limit theorem and because we assume the null hypothesis is true they are centered around population \(\mu\). This distribution is called sampling distribution and it is only imaginative, we do not construct it from the data, it comes from the assumption about the null hypothesis.
We usually run only 1 experiment giving us point estimate \(\hat{\mu}\) of population mean \(\mu\). If \(\hat{\mu}\) lies out of where eg. 95% of samples from the imaginative sampling distribution would lay, we say that we collected evidence that shows tha under 95% significance level (\(0.95 = 1-\alpha\)), we can reject the null hypothesis as being valid.
Note that this does not say much about a probability of the null hypothesis to be true or false. It can only reject the null hypothesis.

STAT 414 / 415, Probability Theory and Mathematical Statistics
p-Value¶
p-Value is the probability of getting point estimates \(\hat{\mu}_i\) from running multiple experiments equally or more extreme than the one point estimate \(\hat{\mu}\) we’ve got from our real experiment under sampling distribution based on our null hypothesis. If p-value is below 5%, we reject the null hypothesis under 95% significance level.
Note that p-value does not talk about probability of where we can expect \(\mu\). It talks about probability of getting such or more extreme result.
Let’s illustrate p-value under some null hypothesis and stopping criteria. Most of all imaginative experiment results falls around the mean of sampling distribution (from central limit theorem). Some fall beyond actual outcome. p-value is proportion of the cloud at actual outcome and beyond.
p-Value Depends on How we Perform the Test¶
Many of the following examples are taken from very well written book John Kruschke Doing Bayesian Data Analysis.
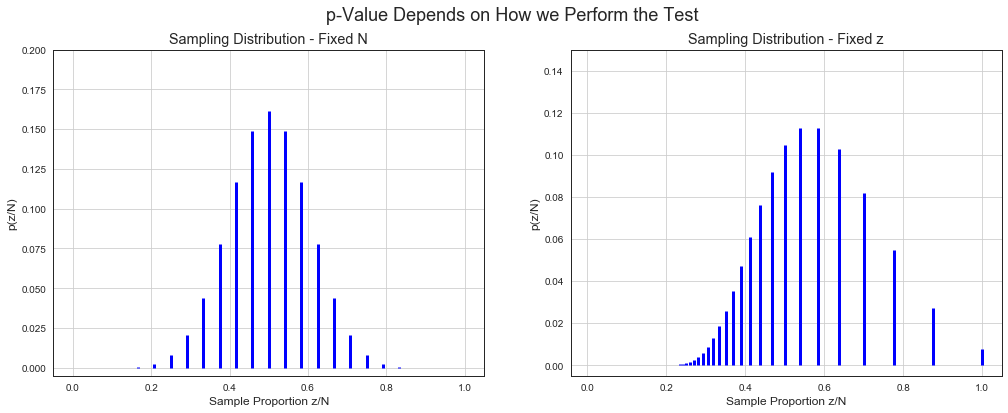
Test if a coin is a fair coin (\(\theta = \frac{1}{2}\)) or not given a sample consisting of \(N\) tosses with \(z\) heads.
# simulation
z = 7
N = 24
theta = 0.5
b = st.binom(N, theta)
zs = np.arange(0., N + 1)
ns = np.arange(z, 1000.)
proba_n = b.pmf(zs)
left_tail_n = np.sum(b.pmf(zs[zs <= 7]))
proba_z = z/ns * st.binom.pmf(z, ns, theta)
left_tail_z = 1 - np.sum(z / ns[ns < N] * st.binom.pmf(z, ns[ns < N], theta))
fig, axx = plt.subplots(nrows=1, ncols=2, figsize=(17, 6));
fig.suptitle('p-Value Depends on How we Perform the Test', fontsize=18)
ax = axx[0]
ax.vlines(zs/N, 0, proba_n, colors='b', linestyles='-', lw=3);
ax.set_ylim((-0.005, 0.2));
ax.set_xlabel('Sample Proportion z/N');
ax.set_ylabel('p(z/N)');
ax.grid();
ax.set_title('Sampling Distribution - Fixed N');
ax = axx[1]
ax.vlines(z/ns, 0, proba_z, colors='b', linestyles='-', lw=3);
ax.set_ylim((-0.005, 0.15));
ax.set_xlabel('Sample Proportion z/N');
ax.set_ylabel('p(z/N)');
ax.grid()
ax.set_title('Sampling Distribution - Fixed z');
# simulation
fig, axx = plt.subplots(nrows=1, ncols=2, figsize=(17, 6));
fig.suptitle('p-Value Depends on How we Perform the Test', fontsize=18)
ax = axx[0]
ax.vlines(zs/N, 0, proba_n, colors='b', linestyles='-', lw=3);
ax.plot([float(z)/N], [0.], marker='o', color='k', markersize=10);
ax.text(.1, .14, 'N = %0.0f\nz = %0.0f\np = %0.3f' % (N, z, left_tail_n), fontsize=18)
ax.set_ylim((-0.005, 0.2));
ax.set_xlabel('Sample Proportion z/N');
ax.set_ylabel('p(z/N)');
ax.grid();
ax.set_title('Sampling Distribution - Fixed N');
ax.arrow(float(z)/N, 0., -float(z)/N, 0., width=.001, head_width=.008, overhang=0.2, color='k');
ax = axx[1]
ax.vlines(z/ns, 0, proba_z, colors='b', linestyles='-', lw=3);
ax.plot([float(z)/N], [0.], marker='o', color='k', markersize=10);
plt.text(.1, .1, 'N = %0.0f\nz = %0.0f\np = %0.5f' % (N, z, left_tail_z), fontsize=18)
ax.set_ylim((-0.005, 0.15));
ax.set_xlabel('Sample Proportion z/N');
ax.set_ylabel('p(z/N)');
ax.grid()
ax.set_title('Sampling Distribution - Fixed z');
ax.arrow(float(z)/N, 0., -float(z)/N, 0., width=.001, head_width=.006, overhang=0.2, color='k');
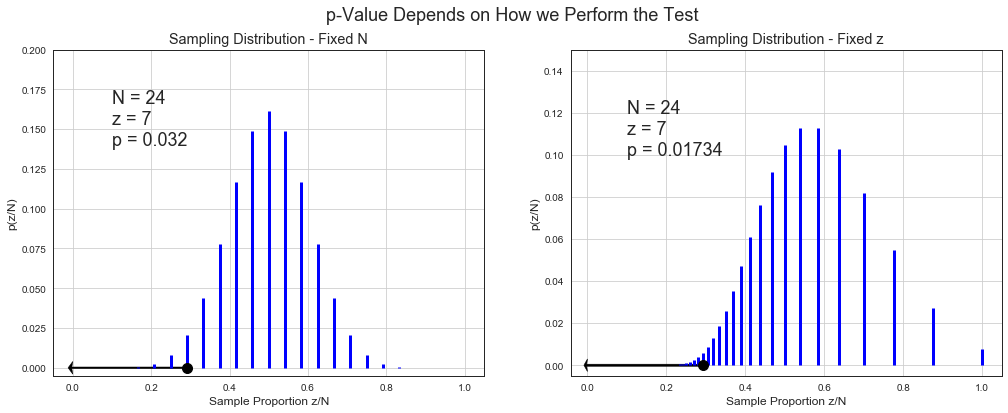
Quiz¶
You’ve run an A/B test. Your A/B testing software has given you a p-value of \(0.03\). Which of the following is true? (Several or none of the statements may be correct.)
You have disproved the null hypothesis (that is, there is no difference between the variations).
The probability of the null hypothesis being true is 0.03.
You have proved your experimental hypothesis (that the variation is better than the control).
The probability of the variation being better than control is 97%.
Chris Stucchio, Bayesian A/B Testing at VWO
All above statements are wrong!
NHST Pros¶
Simplicity.
Binary thinking.
Studied well, tools and knowledge available.
NHST Cons¶
Sad faces of experimenters when p-value >= 5% and we don’t know if \(H_0\) or \(H_1\) is valid (this happens 90% of times!).
Needs statisticians to explain and overcome many misleading pitfalls when not running 100% correctly.
Unintuitive reasoning based on sampling distributions.
Bayesian Analysis¶
Bayesian analysis solves all our cons of NHST.
How Do We Update Our Belief in Things?¶
We assume our own belief for an event to happen (eg. someone gets sick) from colloquial/anecdotal knowledge.
When we have more evidence pointing toward (away from) the event, we increase (decrease) our beliefe for an event to happen.
is equal to the probability of the evidence being caused by the event multiplied by the probability of the event itself.
Example¶
Patient has tested positive for disease \(d\).
The test used has hit rate (recall) of 99% - probability of testing positive \(t\) given patient has a disease.
The test used has false alarm rate (fpr) of 5% - probability of testing positive \(t\) given patient does not have a disease.
The disease is rare striking only 1 out of 1,000 people.
What do you think is the probability of the patient having the disease when his test was positive?
Example¶
Patient has tested positive for disease \(d\).
The test used has accuracy of 99% - probability of testing positive \(t\) given patient has disease \(d\)
The test used has false alarm rate of 5% - probability of testing positive \(t\) given patient does not have a disease.
The disease is rare striking only 1 out of 1,000 people.
The probability that the patient actually has the disease (given he has tested positive) is:
\(P(t\,|\,d) = 0.99\)
\(P(d) = 0.001\)
\(P(t)\) overall probability of test returning a positive value is \(P(t) = P(t\,|\,d)\,P(d) + P(t\,|\,\neg d)\,P(\neg d) = 0.05\)
\(P(t\,|\,\neg d) = 0.05\)
Different (Better) Setting?¶
But the patient went to see a doctor, the prior of 1 out of 1,000 is not a reality. Doctor’s data show that 1 patient has the disease out of 100 of those who enter the office.
Bayesian Inference¶
# prior, likelihood, posterior
colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple", "pink", "brown", "red", "light blue", "green"]
colors = sns.xkcd_palette(colors)
N = 50
z = 35
theta = z/N
rv = st.binom(N, theta)
mu = rv.mean()
a, b = 20, 20
prior = st.beta(a, b)
post = st.beta(z+a, N-z+b)
ci = post.interval(0.95)
thetas = np.linspace(0, 1, 200)
plt.figure(figsize=(20, 7))
plt.subplot(131)
plt.plot(thetas, prior.pdf(thetas), label='Prior', c=colors[1], lw=3)
plt.fill_between(thetas, 0, prior.pdf(thetas), color=colors[1]);
plt.xlabel(r'$\theta$', fontsize=14)
plt.ylabel(r'$P(\theta) = beta(\theta\ |\ a, b)$', fontsize=16)
plt.legend();
plt.grid()
plt.ylim((-0.5, 9));
plt.title('Prior');
plt.subplot(132)
plt.plot(thetas, N*st.binom(N, thetas).pmf(z), label='Likelihood', c=colors[0], lw=3)
plt.fill_between(thetas, N*st.binom(N, thetas).pmf(z), color=colors[0]);
plt.xlabel(r'$\theta$', fontsize=14)
plt.ylabel(r'$P(z,N\ |\ \theta)$', fontsize=16)
plt.legend();
plt.grid()
plt.ylim((-0.5, 9));
plt.title('Likelihood');
plt.subplot(133)
plt.plot(thetas, prior.pdf(thetas), label='Prior', c=colors[1], lw=3, dashes=[2, 2])
plt.plot(thetas, N*st.binom(N, thetas).pmf(z), label='Likelihood', c=colors[0], lw=3,dashes=[2, 2])
plt.plot(thetas, post.pdf(thetas), label='Posterior', c=colors[2], lw=3)
plt.fill_between(thetas, 0, post.pdf(thetas), color=colors[2]);
# plt.axvline((z+a-1)/(N+a+b-2), c=colors[2], linestyle='dashed', alpha=0.8, label='MAP', lw=3)
# plt.axvline(mu/N, c=colors[0], linestyle='dashed', alpha=0.8, label='MLE', lw=3)
plt.xlim((0, 1));
plt.ylim((-0.5, 11));
plt.axhline(post.pdf(ci[0]), ci[0], ci[1], c='black', label='95% HDI', lw=3);
plt.axvline(ci[0], 0.5/11.5, (post.pdf(ci[0])+0.5)/11.5, c='black', linestyle='dotted', lw=3);
plt.axvline(ci[1], 0.5/11.5, (post.pdf(ci[0])+0.5)/11.5, c='black', linestyle='dotted', lw=3);
plt.xlabel(r'$\theta$', fontsize=14)
plt.ylabel(r'$P(\theta\ |\ z,N) = beta(\theta\ |\ a+z, b+N-z)$', fontsize=16)
plt.legend();
plt.ylim((-0.5, 9));
plt.grid()
plt.title('Posterior');
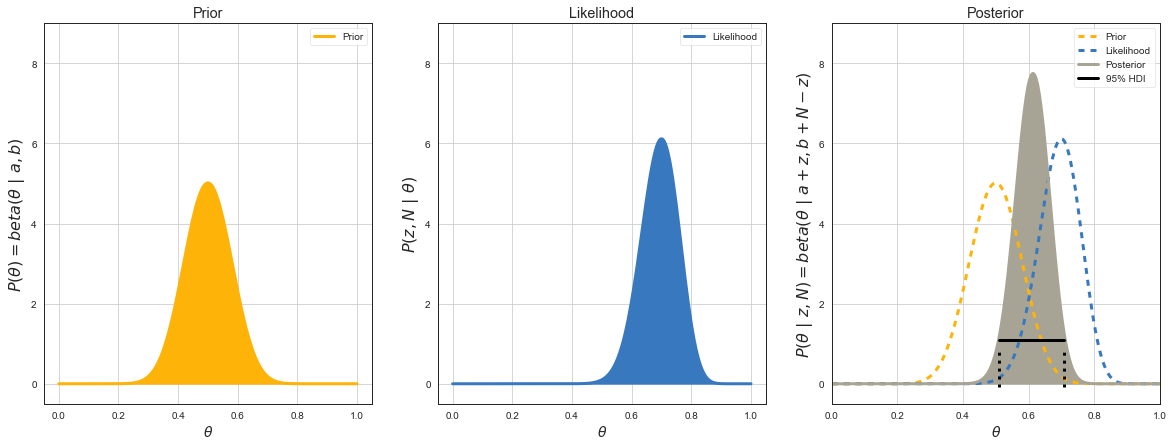
Bayes Rule¶
where \(\theta\) is our estimation (eg. CTR), \(D\) data we measured (\(z\) heads from \(N\) tosses).
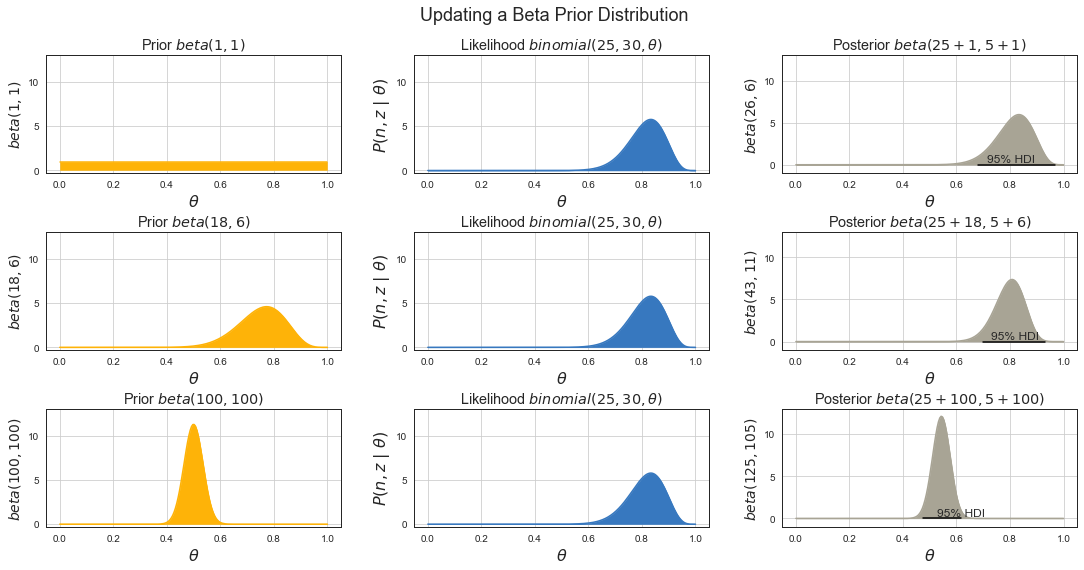
Impact of Prior to Posterior¶
# prior to posterior
N = 30
z = 25
theta = z/N
rv = st.binom(N, theta)
thetas = np.linspace(0, 1, 200)
fig, axx = plt.subplots(nrows=3, ncols=3, figsize=(15, 8));
fig.suptitle('Updating a Beta Prior Distribution', fontsize=18);
fig.tight_layout(rect=[0, 0.03, 1, 0.92])
fig.subplots_adjust(hspace=0.5, wspace=0.25)
colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple", "pink", "brown", "red", "light blue", "green"]
colors = sns.xkcd_palette(colors)
def plot_column(a, b, z, N, thetas, axx, y_lim_top=13):
prior = st.beta(a, b)
post = st.beta(z+a, N-z+b)
ci = post.interval(0.95)
ax = axx[0]
ax.plot(thetas, prior.pdf(thetas), c=colors[1]);
ax.set_xlabel(r'$\theta$', fontsize=16);
ax.set_ylabel(r'$beta(%d, %d)$' % (a, b), fontsize=14);
ax.set_title(r'Prior $beta(%d, %d)$' % (a, b));
ax.set_ylim(bottom=-0.3);
ax.grid()
if y_lim_top is not None:
ax.set_ylim(top=y_lim_top);
ax.fill_between(thetas, 0, prior.pdf(thetas), color=colors[1]);
ax = axx[1]
pmf = N*st.binom(N, thetas).pmf(z)
ax.plot(thetas, pmf, label='Likelihood', c=colors[0]);
ax.set_xlabel(r'$\theta$', fontsize=16);
ax.set_ylabel(r'$P(n,z\ |\ \theta)$', fontsize=16);
ax.set_title(r'Likelihood $binomial(%d, %d, \theta)$' % (z, N));
ax.set_ylim(bottom=-0.3);
if y_lim_top is not None:
ax.set_ylim(top=y_lim_top);
ax.grid()
ax.fill_between(thetas, 0, pmf, color=colors[0]);
ax = axx[2]
ax.plot(thetas, post.pdf(thetas), label='Posterior', color=colors[2]);
ax.fill_between(thetas, 0, post.pdf(thetas), color=colors[2]);
ax.axhline(0, ci[0], ci[1], c='black', label='95% CI');
# ax.text(ci[0]-0.1, .5, '%0.3f' % ci[0], fontsize=12);
# ax.text(ci[1], .5, '%0.3f' % ci[1], fontsize=12);
ax.text(ci[0]+0.05, .3, '95%% HDI' % ci[0], fontsize=12);
ax.set_xlabel(r'$\theta$', fontsize=16);
ax.set_ylabel(r'$beta(%d, %d)$' % (z+a, N-z+b), fontsize=14);
ax.set_title(r'Posterior $beta(%d + %d, %d + %d)$' % (z, a, N-z, b));
ax.set_ylim(bottom=-1);
ax.grid()
if y_lim_top is not None:
ax.set_ylim(top=y_lim_top);
plot_column(1, 1, z, N, thetas, axx[:][0])
plot_column(18, 6, z, N, thetas, axx[:][1])
plot_column(100, 100, z, N, thetas, axx[:][2])
Bayes Rule for Conversions¶
Estimate conversion rate \(\theta\) from \(N\) impressions of an online ad that recorded \(z\) clicks.
Or estimate the bias \(\theta\) of a coin given a sample consisting of \(N\) tosses with \(z\) heads.
Where
\(P(z, N\,|\,\theta) = P(z, N\,|\,\theta) = \binom{N}{z}\theta^z(1-\theta)^{N-z}\) is binomial likelihood function of getting test results for different \(\theta\).
\(P(\theta) = beta(\theta\,|\,a, b)\) is our prior belief about where \(\theta\) is before running experiment.
\(P(\theta\,|\,z,N)\) is posterior distribution aka our prior believe updated by the evidence from the experiment results of \(z/N\) of where we can expect \(\theta\) to lie.
\(P(\theta\,|\,z,N) = \text{beta}(\theta\,|\,a + z, b + N - z)\)
Where
\(\text{beta}\) is beta distribution
\(a\) is prior number of successes
\(b\) is prior number of failures
\(N\) number of observations in the test
\(z\) number of successes (conversions) in the test
Beta Distribution¶
# beta distributions
plots = 5
thetas = np.linspace(0, 1, 200)
fig, axx = plt.subplots(nrows=plots, ncols=plots, figsize=(15, 8));
fig.tight_layout(rect=[0, 0.03, 1, 0.95])
fig.subplots_adjust(hspace=0.9, wspace=0.4)
colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple", "pink", "brown", "red", "light blue", "green"]
colors = sns.xkcd_palette(colors)
for a in range(plots):
for b in range(plots):
aa = a+1
bb = b+1
beta = st.beta(aa, bb)
ax = axx[a][b]
pst = beta.pdf(thetas)
ax.plot(thetas, pst, c=colors[1])
ax.fill_between(thetas, 0, pst, color=colors[1]);
ax.set_xlabel(r'$\theta$', fontsize=16);
# ax.set_ylabel(r'$p(\theta|a=%d, b=%d)$' % (aa, bb), fontsize=14);
ax.set_title(r'$beta(%d, %d)$' % (aa, bb));
ax.grid()
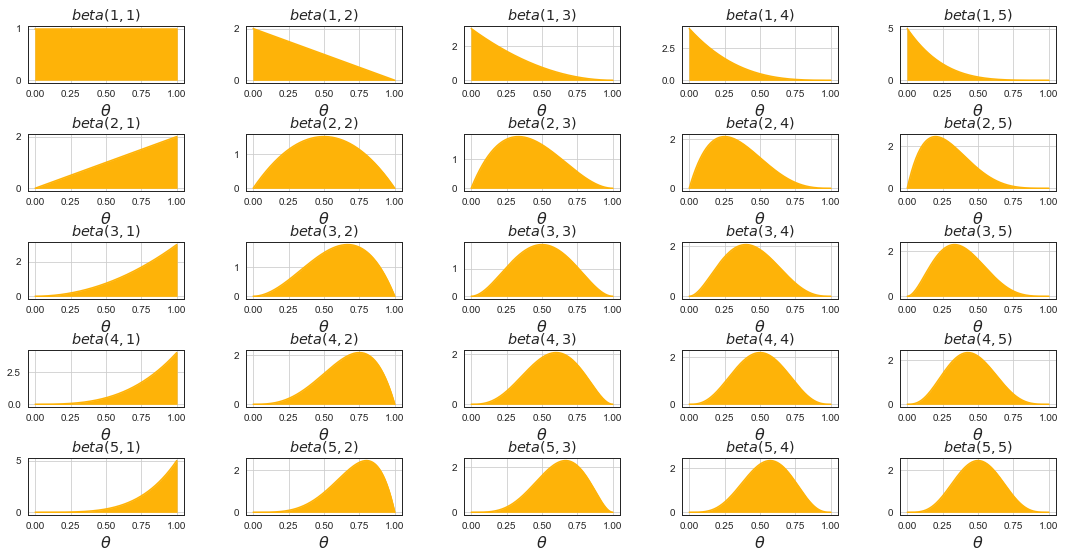
Is Bayesian Analysis More Informative?¶
NHST does not work with priors while BA makes them explicit and part of the reasoning process.
NHST uses sampling distribution for inference while BA uses posterior distribution.
Sampling distribution tells us probabilities of possible data given a particular (null) hypothesis.
Posterior distribution tells us credibilities of possible hypothesis (values of \(\theta\)) given the data.
Good discussion of these properties from frequentists point of view could be found in:
Decision Rules¶
NHST - Reject null hypothesis if p-value \(\lt 5\%\).
Bayes
Reject null hypothesis if 95% HDI is outside of Region of Practical Equivalence (ROPE) defined around null value.
Accept null hypothesis if 95% HDI is completely inside of Region of Practical Equivalence.
Decision Rules and False Positives¶
NHST has 100% false positive rate when doing sequentional testing stopped when p-value is below 5% with enough patience. Reasons:
NHST only rejects null hypothesis (cannot accept one).
There is non zero probability to get long stretch of extreme values that move p-value below 5%.
Simulation of Decision Making¶
There are simulated data of 2000 flips with p-value calculated after every flip below. The first set is for case when null hypothesis of \(\theta = 0.5\) is true. The second set is for case when null hypothesis is not true.
Graph with \(z/N\) shows proportion of \(z\) in \(N\) flips after every flip. Graph with p-value shows p-value calculated for cumulated data after every flip.
Graph with 95% HDI shows 95% HDI intervals after every flip as vertical line. Decision rule based on accepting null hypothesis when 95% HDI interval is completely within ROPE (dashed lines for \(\theta = 0.45\) and \(\theta = 0.55\)) is much stable than NHST decision rule although it has some false positives when not enough data are available.
# null hypothesis is true
theta = 0.5
N = 2000
ns = np.arange(1, N+1)
zs = np.array(st.bernoulli.rvs(theta, size=N))
zs = np.cumsum(zs)
# np.save('zs_nh_true.npy', zs, allow_pickle=False, fix_imports=False)
zs = np.load('./imlp3_files/zs_nh_true.npy')
theta = 0.5
p_values = [np.sum(st.binom(n, theta).pmf(np.arange(0, zs[n-1] + 1))) for n in ns]
posts = st.beta(1 + zs, 1 + ns - zs)
cs = posts.interval(.95)
fig, axx = plt.subplots(nrows=3, ncols=1, figsize=(17, 10));
fig.suptitle(r'Sequentional Testing, Null Hypothesis is True - $\theta = 0.5$', fontsize=18);
fig.tight_layout(rect=[0, 0.03, 1, 0.95])
fig.subplots_adjust(hspace=0.3, wspace=0.25)
colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple", "pink", "brown", "red", "light blue", "green"]
colors = sns.xkcd_palette(colors)
ax = axx[0]
ax.plot(ns, zs/ns, lw=7);
ax.axhline(0.5, ls='dashed', c='gray', lw=2)
ax.grid()
ax.set_ylabel(r'$z/N$')
ax.set_ylim((-0.05, 1.05))
ax = axx[1]
ax.scatter(ns, p_values, c=['b' if p_values[n] < 0.05 else 'k' for n in range(0, N)], lw=3);
ax.axhline(0.05, ls='dashed', c='gray', lw=2)
ax.grid()
ax.set_ylabel('p-value')
ax.set_ylim(bottom=-0.05)
ax = axx[2]
ax.vlines(ns, cs[0], cs[1], colors=['b' if cs[0][n] >= 0.45 and cs[1][n] <= 0.55 else 'k' for n in range(0, N)], linestyles='-')
ax.axhline(0.45, ls='dashed', c='gray', lw=2)
ax.axhline(0.55, ls='dashed', c='gray', lw=2)
ax.grid()
ax.set_ylim((-0.05, 1.05))
ax.set_ylabel('Accepting 95% HDI')
ax.set_xlabel('Flips');
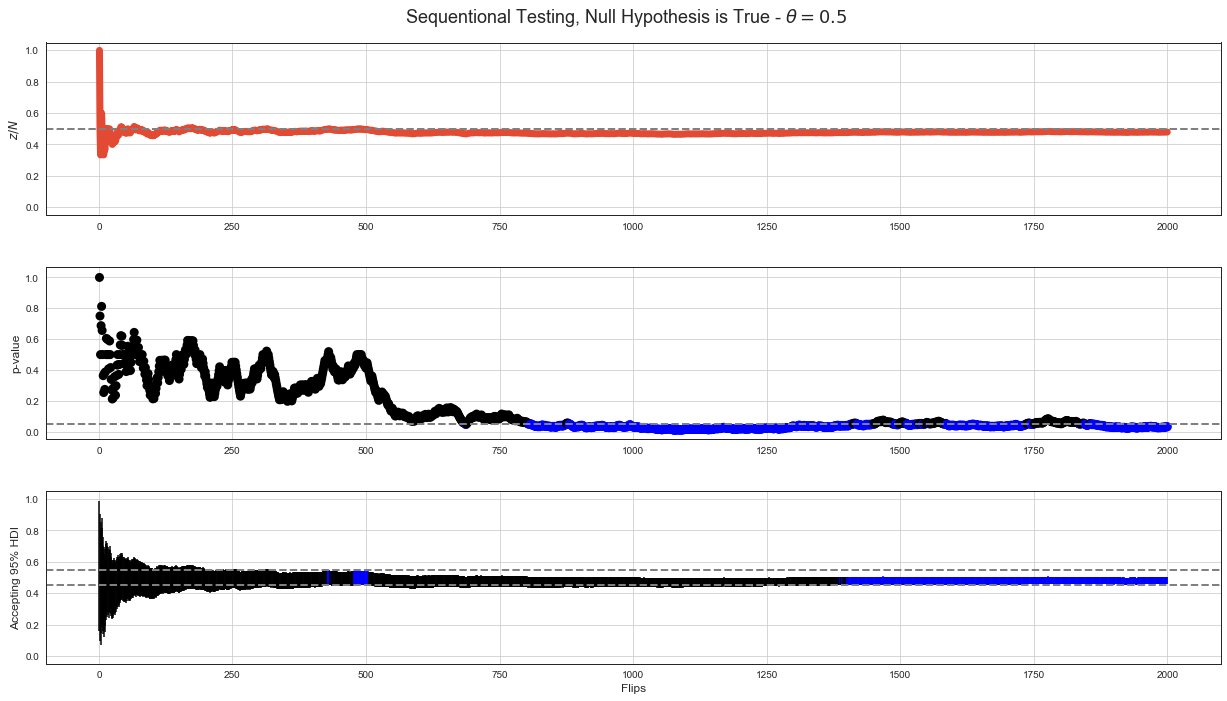
Null Hypothesis is True¶
p-value < 5% based decision rule shows long stretches of p-value < 5% when if we stopped the test there, it would falsly reject null hypothesis. This example shows that even around flip 2000 it would falsly reject true null hypothesis.
95% HDI decision rule shows much stable behavior starting fairy stably accepting true null hypothesis around step 1300.
# null hypothesis is false
theta = 0.7
zs1 = np.array(st.bernoulli.rvs(theta, size=N))
zs1 = np.cumsum(zs1)
# np.save('zsa.npy', zs1, allow_pickle=False, fix_imports=False)
zs1 = np.load('./imlp3_files/zs_null_false.npy')
theta = 0.7
p_values = [np.sum(st.binom(n, theta).pmf(np.arange(0, zs1[n-1] + 1))) for n in ns]
posts = st.beta(1 + zs1, 1 + ns - zs1)
cs = posts.interval(.95)
fig, axx = plt.subplots(nrows=3, ncols=1, figsize=(17, 10));
fig.suptitle(r'Sequentional Testing, Null Hypothesis is False - $\theta = %0.2f$' % theta, fontsize=18);
fig.tight_layout(rect=[0, 0.03, 1, 0.95])
fig.subplots_adjust(hspace=0.3, wspace=0.25)
colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple", "pink", "brown", "red", "light blue", "green"]
colors = sns.xkcd_palette(colors)
ax = axx[0]
ax.plot(ns, zs1/ns, lw=7);
ax.axhline(0.5, ls='dashed', c='gray', lw=2)
ax.set_ylabel(r'$z/N$')
ax.grid()
ax.set_ylim((-0.05, 1.05))
ax = axx[1]
ax.scatter(ns, p_values, c=['b' if p_values[n] < 0.05 else 'k' for n in range(0, N)], lw=3);
ax.axhline(0.05, ls='dashed', c='gray', lw=2)
ax.set_ylabel('p-value')
ax.grid()
ax.set_ylim(bottom=-0.05)
ax = axx[2]
ax.vlines(ns, cs[0], cs[1], colors=['b' if cs[0][n] > 0.55 else 'k' for n in range(0, N)], linestyles='-')
ax.axhline(0.45, ls='dashed', c='gray', lw=2)
ax.axhline(0.55, ls='dashed', c='gray', lw=2)
ax.set_ylim((-0.05, 1.05))
ax.set_ylabel('Rejecting 95% HDI')
ax.grid()
ax.set_xlabel('Flips');
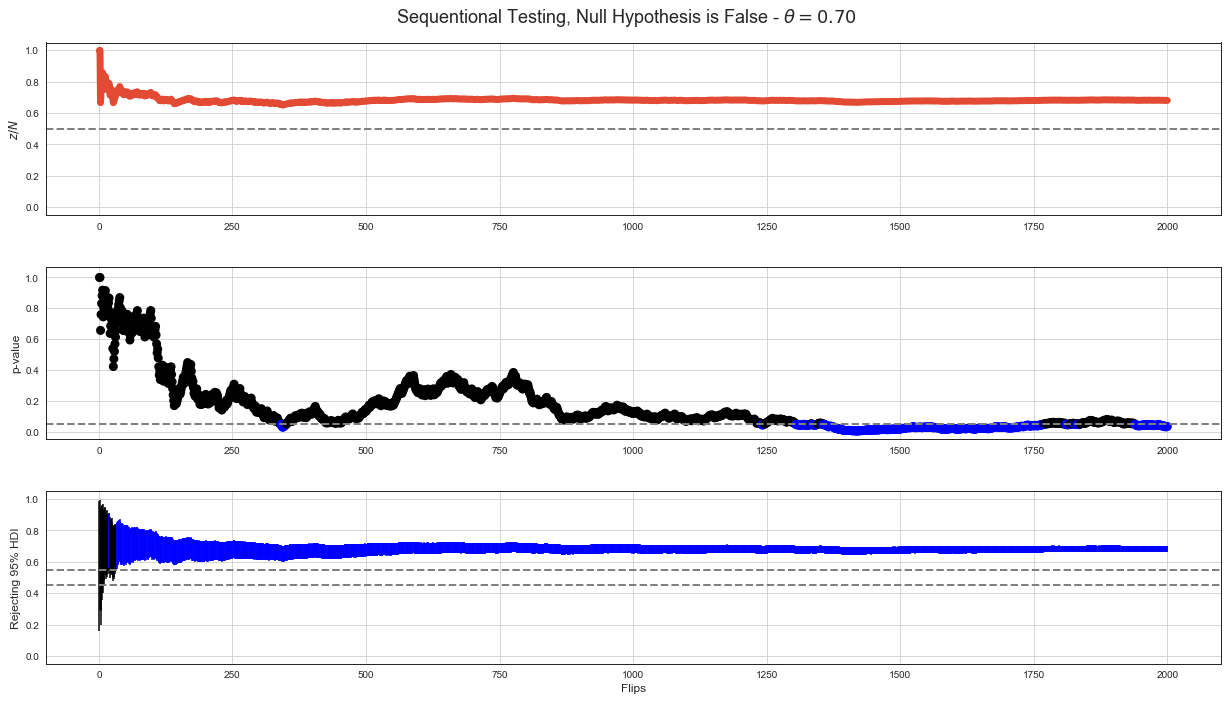
Null Hypothesis is False¶
p-value < 5% based decision rule starts correctly rejecting null hypothesis after step 1300. There’s also stretch around 1800 steps when it stops rejecting null hypothesis.
95% HDI decision rule starts rejecting null hypothesis much sooner and shows stable behavior.
Probabilistic Results¶
We measure experiment results (conversion rates) and calculate their posterior distributions. We sample many (>= 1,000,000) samples from these posterior distributions and calculate following properties of these samples per variant.
Improvement
Probability to Beat Baseline
Probability to Be the Best
N = 10000 # samples per variant in experiment
S = 10000 # number of samples taken from posterior distribution
theta_a = 0.1 # simulated conversion rates of three variants
theta_b = 0.11
theta_c = 0.12
ns = np.arange(1, N+1)
zs_a = np.cumsum(np.array(st.bernoulli.rvs(theta_a, size=N))) # cumulated number of conversion
zs_b = np.cumsum(np.array(st.bernoulli.rvs(theta_b, size=N)))
zs_c = np.cumsum(np.array(st.bernoulli.rvs(theta_c, size=N)))
posts_a = st.beta(1 + zs_a, 1 + ns - zs_a) # for each measurement, take its beta distribution, we have N betas per variant
posts_b = st.beta(1 + zs_b, 1 + ns - zs_b)
posts_c = st.beta(1 + zs_c, 1 + ns - zs_c)
posts_a_rvs = posts_a.rvs(size=(S, N)) # sample S samples from each of N betas
posts_b_rvs = posts_b.rvs(size=(S, N))
posts_c_rvs = posts_c.rvs(size=(S, N))
improvement = np.median(((posts_c_rvs - posts_a_rvs) / posts_a_rvs), axis=0)
beat_baseline = np.sum(np.where(posts_c_rvs > posts_a_rvs, 1, 0), axis=0) / S
pbb = np.argmax(np.array((posts_a_rvs, posts_b_rvs, posts_c_rvs)), axis=0) # who won in 3x S samples in every N samples
pbb_a = np.sum(np.where(pbb == 0, 1, 0), axis=0) / S
pbb_b = np.sum(np.where(pbb == 1, 1, 0), axis=0) / S
pbb_c = np.sum(np.where(pbb == 2, 1, 0), axis=0) / S
Improvement¶
Median improvement that we can expect over the baseline if we full scale the variant.
# improvement of C against A
f = 50
fig = plt.figure(figsize=(12, 3));
plt.plot(ns[f:], improvement[f:], lw=6, c=colors[0]);
plt.grid();
plt.title('Improvement of C against A');
plt.xlabel('Samples in Experiment');
plt.ylabel('Improvement');
plt.ylim((-.3, 1));
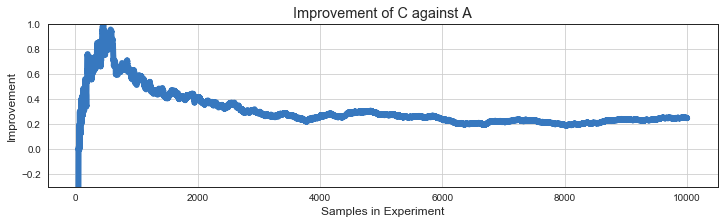
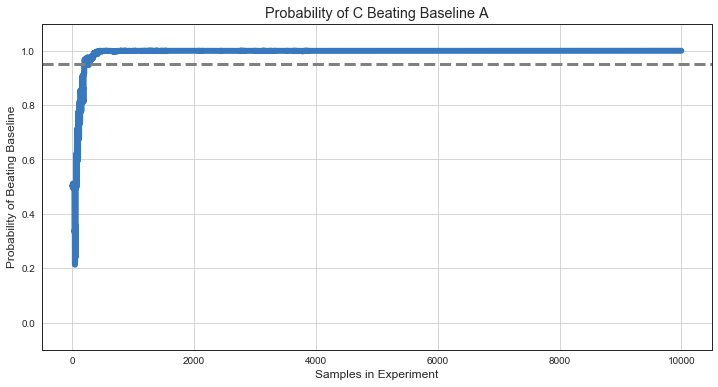
Probability to Beat Baseline¶
Number of times treatment variant sample beats control (baseline) variant sample.
# probability of C beating baseline A
fig = plt.figure(figsize=(12, 6));
plt.plot(ns, beat_baseline, lw=6, c=colors[0]);
plt.axhline(0.95, ls='dashed', c='gray', lw=3)
plt.grid();
plt.ylim((-0.1, 1.1))
plt.title('Probability of C Beating Baseline A');
plt.xlabel('Samples in Experiment');
plt.ylabel('Probability of Beating Baseline');
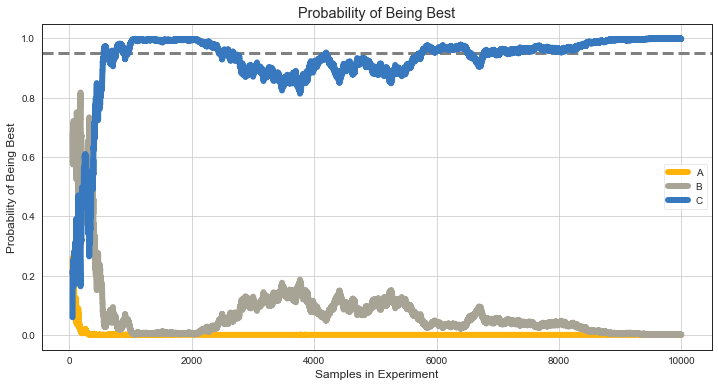
Probability to Be the Best¶
Number of times variant sample beats all other variants samples.
# probability of being best
fig = plt.figure(figsize=(12, 6));
plt.axhline(0.95, ls='dashed', c='gray', lw=3)
plt.plot(ns[f:], pbb_a[f:], lw=6, label='A', c=colors[1]);
plt.plot(ns[f:], pbb_b[f:], lw=6, label='B', c=colors[2]);
plt.plot(ns[f:], pbb_c[f:], lw=6, label='C', c=colors[0]);
plt.grid();
plt.legend();
plt.title('Probability of Being Best');
plt.xlabel('Samples in Experiment');
plt.ylabel('Probability of Being Best');
Resources¶
Prem S. Mann Introductory Statistics 7nd Edition
R. Kohavi, A. Deng Seven Rules of Thumb for Website Experimenters
John Kruschke Doing Bayesian Data Analysis
S. Gupta, R. Kohavi et al. Top Challenges from the first Practical Online Controlled Experiments Summit
H. Hohnhold, D. O’Brien, D. Tang Focusing on the Long-term: It’s Good for Users and Business